Frequently Asked Questions
This document is meant to answer commonly asked questions and reasons for job failures in Qualcomm® AI Hub. Please use this as a point of reference and feel free to ask any questions in AI Hub Slack.
General
Do models submitted to AI Hub run on real devices?
Yes, we have thousands of real devices hosted through multiple device farms. When you use AI Hub and run a model on a particular device, we fetch the device, install an OS and all necessary frameworks needed to run the model on the device. We then run your model on that device to capture all the metrics presented on AI Hub. Once this process is completed, we release the device. We repeat this for every job submitted to AI Hub. To see all the devices we have available you can run qai-hub list-devices.
How does device provisioning on AI Hub work? Can many users run models on different devices at the same time on AI Hub?
Yes. We have many devices, and we can run models in parallel across all of them. When a real device is procured, it only has your specific model running on it.
Yes, as users submit jobs separate devices are procured for each to provide accurate metrics.
How do I set up my API token to submit jobs on AI Hub?
Once you’ve created a Qualcomm MyAccount, login to Qualcomm® AI Hub and navigate to the settings page to grab your unique API token. We recommend watching the how-to video on this topic for detailed instructions.
How do I add others from my team or from another team to view my jobs on AI Hub?
- AI Hub jobs can be shared with your organization automatically. If you’d like to add
a developer on your team, that has an AI Hub account to your organization, please email ai-hub-support@qti.qualcomm.com with the email addresses.
AI Hub jobs can also be shared outside of your organization and with Qualcomm to obtain support. Click the “Share” button, in the top right of any job and specify an email of an AI Hub User and the job (and its associated model assets) will be shared. Access can also be revoked by removing an email address from the job.
Where can I find the models that are already optimized with AI Hub?
You can go to any one of the locations listed below to find models that are pre-optimized with AI Hub, we have 150+ optimized models available today and are constantly adding new ones:
Qualcomm® AI Hub Models, Qualcomm’s Hugging Face, Qualcomm® AI Hub Models
Can I bring my own model and run it on AI Hub?
Yes. This feature is available for anyone to use! Please note that there are known limitations as to which models will succeed. A model may fail to compile for following reasons:
The model is large (i.e. > 2GB).
The model may fail to trace in PyTorch, please follow the error messages and make model changes accordingly:
If a model has a branch (if/else), setting
check_trace=Falseduringtorch.jit.tracesolves the problem.
LLMs/GenAI models may fail out of the box:
These large models often require to be quantized to run effectively on device. Please refer to our LLM recipes for guidance.
Misc. conversion issues:
Conversion might fail internally, please let us know if you hit an error message that is unclear (i.e. internal device error) and we will do our best to investigate the issue in a timely manner. Support for more models is always growing!
If a compile job fails, please make sure the provided input specs are compatible with the model.
To submit your first job on AI Hub, we recommend watching the how-to video on this topic. If you hit any issues, please reach out to us on AI Hub Slack!
Can I try a model from HuggingFace that isn’t in Qualcomm AI Hub Models?
Yes! These are great models to try. If you have a model in mind for your use case that we don’t have listed, check out https://huggingface.co/models and pick a model. You can then import the necessary packages and trace the model ahead of submitting a compilation job. (See below for common errors when submitting a job.)
Can I run a quantized model with AI Hub on a real device?
Yes. We have some quantized models listed in Qualcomm® AI Hub Models, which you can filter by under the model precision section to see their performance. These are quantized with AIMET though they are in the process of being transitioned to use Quantization.
If you’d like to bring your own quantized model, we recommend quantizing with Quantization as it takes unquantized ONNX and quantizes it as output.
How do I run my model on a specific device on Qualcomm® AI Hub?
When you’re submitting your model, you need to specify which device you’d like to target. To get a list of devices
available, run qai-hub list-devices. From there, you can specify a device either by its name or any of its
attributes. For example, device = hub.Device(attributes="qualcomm-snapdragon-845") will run it on any device with
an 845 chip, whereas device=hub.Device("QCS6490 (Proxy)") will specifically run it on the 6490 proxy device. We
also have device families, which you will see, where applicable, next to a device in the list i.e. Google Pixel 3a
Family, Samsung Galaxy S21 Family etc. This is to help with device provisioning times, alleviating long queue times
for a device with a specific name. It will always provide a device of with the same chipset you have specified. Please
use this option when applicable! We recommend watching the how-to video on this topic.
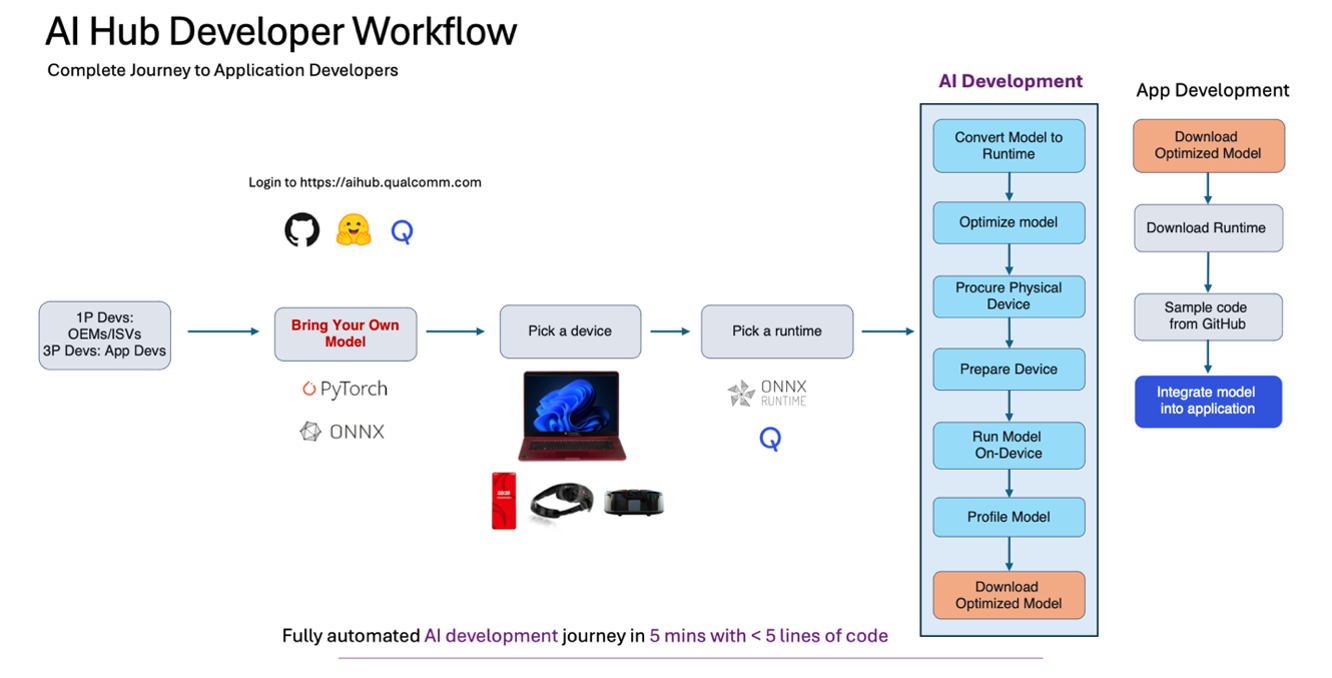
What is the typical developer worflow when using AI Hub?
Step 1: selecting a model for your use case, whether from Qualcomm® AI Hub Models or bringing your own model.
Step 2: submit a compilation job to compile your trained model (PyTorch, ONNX, AIMET quantized models) for the specified device (use qai-hub list-devices to determine the devices available) and desired target runtime.
Step 3: submit a profile job, running your compiled model on a real device hosted in the cloud and analyze the performance (i.e. does it meet your latency targets, memory limits, is it running on the desired compute unit). This is where you’ll get a lot of rich metrics about the performance of your model such as per-layer timing, visualization of each layer, loading and inference times as well as runtime log information which can be critical if your job fails.
Step 4: submit an inference job to upload input data, run inference on a real device and download the output results.
Step 5: perform any necessary post-processing calculations on the on-device output, confirming the accuracy of the model.
Step 6: programmatically download the optimized model, to be integrated into your application. Check out our sample apps for help integrating your model into an application.
Why is my model latency with an inference job different than a profile job?
When you submit a profile job, inference occurs 100 times on the specified device. This is to provide an accurate indication of how long you should expect it to take when bundling it into your application. The first iteration is often the slowest, due to startup time, caches warming up etc. The number of times inference is performed during a profile job is customizable with an option, max_profiler_iterations. An inference job however only runs once on the specified device, as its core purpose is to perform accuracy calculations, to confirm the model is numerically equivalent and ready to be downloaded, to be deployed.
I’ve run my model using AI Hub and downloaded the optimized model, now what?
Great question! The next step is to bundle the model asset into your app, for deployment across your target edge
devices (Mobile, IOT, Compute etc.). We have some sample apps on how to do this and are working on
providing more. Specifically for integrating a .bin file when using Qualcomm® AI Engine Direct, please check out
these docs. We’re actively
working on adding more sample apps and information around this topic. For IOT customers deploying to their Rb3Gen2, we
recommend leveraging Foundries.io in conjunction with your optimized model from AI Hub.
What are the licensing terms of models published on AI Hub? Can I use these models in my apps and release them to users?
AI Hub Models showcases a collection of pre-optimized open-source models. The licenses for each model can be found on the corresponding model page.
What are the licensing terms if I bring my own model, is this now Qualcomm IP?
AI Hub is a platform to optimize models for the device. If you “bring your own model”, the deployed assets you get out of AI Hub typically have the same distribution license as your model. If it’s your own IP then the model is yours to distribute. More details can be found as part of our Terms of Service.
Are there any fees associated with using AI Hub or AI Hub Models in my production applications or integrating to AI Hub for my model testing?
AI Hub, our platform, is currently completely free to use. We encourage you to submit your models, compile them, profile and iterate on performance, submit inference jobs to check the accuracy and download the target asset to bundle in your app.
In our collection of models, there are specific models, provided by model-makers that based on their licenses are for purchase. Please contact us accordingly for more information. If a model is listed as ‘download now’ on aihub.qualcomm.com it is free and open to use. Please check out the license of the model, listed on the model page and use it accordingly.
If AI Hub is running models in the cloud, is it secure? Can other users see my models I’ve uploaded?
Everything you do using AI Hub is private and secure unless you explicitly share with other users. This includes all datasets and models uploaded, and any models, datasets, or metrics created via AI Hub jobs. Customer artifacts are wiped from the temporary storage of physical devices and other cloud compute environments upon job completion. Other users cannot see your private information.
Please refer to the Qualcomm privacy policy for details on how Qualcomm collects and uses data, and email us if you have any further questions.
How do I add team members to my organization?
Each user has their own organization and the user’s models and data are kept securely in their organization with access limited to only them and the people they add to the organization. Let us know if you’d like to add anyone to your organization in AI Hub, that way they can see your jobs and vice versa.
If you’d like to add someone to a specific job, we recommend using the share button in the top right of any job and adding their email address.
How do I know what’s changed with AI Hub?
We post our release notes to AI Hub Slack as they happen! You can also find them in our documentation.
Model Formats
Why does Qualcomm® AI Hub Models only provide TensorFlow Lite results for some models?
If you visit our collection of over 100 pre-optimized models, you may only see TensorFlow Lite or Qualcomm® AI Engine Direct results, depending on the model. We’re working to provide performance results for both paths, in which case you’ll see TorchScript → TensorFlow Lite and TorchScript → Qualcomm® AI Engine Direct, in a drop down and you can select the performance numbers you’d like to see. Additionally, if you’re visiting our Compute Models, you’ll see TorchScript → ONNX Runtime performance results as well, where applicable.
Which path do you recommend? TensorFlow Lite, ONNX Runtime or Qualcomm® AI Engine Direct?
There are some known issues where one path is faster than the other, depending on the model. Our ongoing goal is to track these issues and resolve them, across paths. You can expect them to be more or less the same for most models as we optimize them. At the end of the day, all paths lead to the same QNN and the same hardware so there isn’t anything fundamentally different going on. TensorFlow Lite will access Hexagon NPU via TensorFlow Lite Delegate, ONNX Runtime will access Hexagon NPU via ONNX execution provider and Qualcomm® AI Engine Direct will of course leverage Hexagon NPU.
We recommend TensorFlow Lite for Android developers deploying to mobile devices, ONNX Runtime for Windows developers and those deploying to laptops and Qualcomm® AI Engine Direct depending on the SOC / operating system. We highly recommend trying different runtimes and using the path that provides the best performance for your target device.
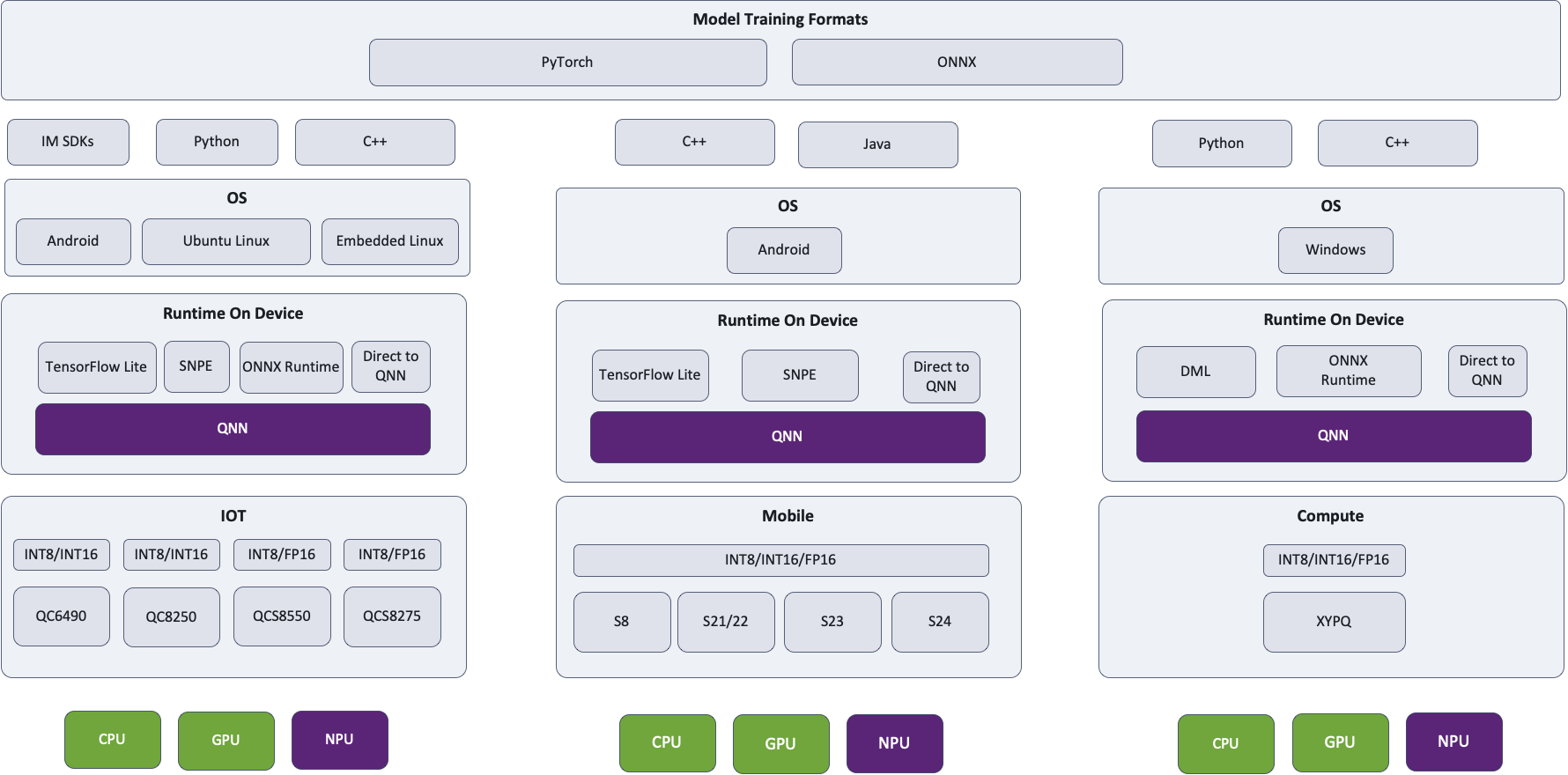
Here is a look at our architecture diagram, where regardless of which path selected and runtime specified, QNN will be used and the Hexagon NPU will be leveraged where applicable. Hub will always run the model on the most optimal compute unit.
Which Qualcomm® AI Engine Direct model format should I use?
The Qualcomm® AI Engine Direct SDK supports three formats for on-device execution: model libraries (.so and .dll), context binaries
(.bin), and deep learning containers (.dlc). There are important differences between these that are likely to
affect runtime performance.
Model libraries (
--target_runtime qnn_lib_aarch64_android) are dynamic libraries that export a single function. Invoking it will use QNN graph building functions to instantiate your model. While this format is OS-specific, the final graph will be optimized for the device on which it’s running, ensuring the best possible inference performance.Deep learning containers (DLCs) are similar to model libraries in that they contain an SoC-agnostic representation of a network. They can additionally embed context binaries for a specific set of targeted SoCs, though this is not yet in common use. Typically, this OS-agnostic format is used to drive QNN-level construction of graph data structures prior to further device-specific optimization.
Context binaries are an OS-agnostic, HTP-specific representation. They are equivalent to loading a model library, preparing the graph for a specific SoC (i.e., allowing QNN to invoke the Hexagon compiler for a specific HTP), and saving the resulting data structures. Since the Hexagon compiler makes assumptions about the HTP in use, context binaries only achieve the best possible performance when a specific HTP is targeted; it is often possible to use binaries built for older devices on newer chips, but performance may suffer.
To achieve best performance, be sure to specify the correct
soc_modeltoqnn-context-binary-generator. You can find the correct value by consulting the table of supported Snapdragon Devices in the Qualcomm® AI Engine Direct Overview, also available in the SDK underdocs/QNN/index.htmland then following the link toOverview. It is also printed near the top of every Qualcomm® AI Hub Runtime log targeting a device with a Qualcomm® SoC.
Qualcomm® AI Engine Direct Model Format Summary
Format |
Backends |
OS Agnostic |
SoC Agnostic |
Time to Load |
Inference Performance |
|---|---|---|---|---|---|
Library |
Any |
No |
Yes |
Longer |
Optimal |
DLC |
Any |
Yes |
Yes |
Longer [1] |
Optimal |
Context Binary |
HTP |
Yes |
No |
Fastest |
Optimal [2] |
Can I deploy an asset from a proxy device onto real hardware?
TL;DR – TensorFlow Lite and ONNX Runtime assets should be fine, QNN model formats may have issues.
In the past, proxy devices were added to AI Hub as a way to provide profiling and inference access to devices with SoCs with similar performance characteristics to popular devices that are unsupported by AI Hub. For example, the QCS6490 found in the RB3 Gen 2 is essentially the same chip as the SM7325 found in several mobile devices. While this can be very useful for benchmarking and accuracy assessment, challenges can arise when producing QNN model formats:
Model libraries are OS-specific. Proxies typically run Android, but the real devices might use Linux.
Context binaries are SoC-specific. While we expect that targeting proxy devices will provide good performance on real devices, this is not a documented guarantee.
In some cases, an entirely different flavor of QNN SDK is used. For example, all automotive proxy devices are mobile devices, but all Cockpit, ADAS, and Flex devices require the use of a specific automotive SDK that has knowledge of the differences between auto and mobile chips of the same generation (e.g., fp16 support on the SA8295P’s V68 HTP).
Fortunately, third party frameworks avoid all of these issues by performing optimization at load time, making TensorFlow Lite and ONNX Runtime assets good choices to deploy in this situation.
Passing Options
How do I specify a compute unit?
When submitting any type of job on AI Hub, use the option --compute_unit <units> to specify which compute unit you
would like the model to run on. If you would like to specify more than one compute unit, separate it by a comma i.e.,
--compute_unit npu,cpu. We recommend watching our
how-to video on this topic.
How do I specify a target runtime?
Qualcomm® AI Hub supports TensorFlow Lite, ONNX Runtime, and Qualcomm® AI Engine Direct (context binary and model library) as target runtimes. Use the
--target_runtime <runtime> option when submitting a compile job to specify a runtime. We recommend checking out our
how-to video on this topic.
How do I make sure I’m leveraging the NPU?
Each target runtime has its own strategy to make the best use of available hardware. There is a tradeoff between performance and capability: NPUs tend to provide the best performance but are most limited in what they can compute. Conversely, CPUs are not optimized for neural network inference, but can execute any operation. Runtimes that support multiple hardware backends generally run as much of a network as possible on NPU before falling back to GPU or CPU.
To enable NPU usage, runtimes must (1) be configured to use it and (2) networks should avoid using unsupported operations or parameters.
By default, AI Hub configures runtimes supporting fallback to use the NPU before degrading to GPU and/or CPU. To
require use of the NPU, specify the compile/runtime option --compute_unit npu. Also consider using a QNN target
runtime, such as qnn_lib_aarch64_android.
Common reasons for layers falling off the NPU include unsupported op or unsupported rank (rank ≥ 5 support is more limited). When this happens on runtimes that support heterogeneous dispatch (e.g., TensorFlow Lite), these layers should simply fall back to GPU or CPU. In some cases, the entire network falls off the NPU. This may happen when a more unexpected error occurs during the on-device preparation of the network. The network will in such case execute on GPU or CPU. Please reach out on AI Hub Slack if this happens, and we’re happy to look at the job.
How do I specify optimization options?
By default, AI Hub will always optimize models for runtime performance. On occasion, this can be problematic when the time to do so is prohibitive: some large models can cause jobs to time out because the Hexagon compiler simply has too much work to do. Rarely, higher optimization levels produce worse code. In such cases, it may make sense to lower the optimization level. How you do so depends on the target runtime environment.
For Qualcomm® AI Engine Direct targeting the NPU (e.g.,
--target_runtime=qnn_lib_aarch64_android --compute_unit all) use--qnn_options=default_graph_htp_optimization_value=xwherexis1or2. Note that Hexagon compilation happens on device when usingqnn_lib_*, but runs ahead of time during model conversion when targetingqnn_context_binary.For TensorFlow Lite delegating to Qualcomm® AI Engine Direct (i.e.,
--target_runtime=tflite) with successful delegation to the NPU, use--tflite_options=kHtpOptimizeForPrepare, which has the effect of setting the QNN optimization level to1. Hexagon compilation always happens on device when targetingtflite.
Common job failures and known issues
My compilation job failed with an error message that an op was missing. What can I do?
If you received an error such as Failure occurred in the ONNX to Tensorflow conversion: Op 'xx' is not yet
implemented. Feel free to reach out to us on AI Hub Slack. We may be able to prioritize adding op support (or it may
already been in progress). If not, we can help provide a workaround where applicable.
My job failed even though I passed an option listed on the documentation, what do I do?
Make sure that you’re passing the option for the right job type (e.g., compile vs profile). For example,
--quantize_full_type is a compile job option; passing it to a profile job will result in a failure. If you are still
encountering issues, please reach out on AI Hub Slack.
My model from Hugging Face failed due to “DictConstruct” not supported. What do I do?
We recommend setting model.config.return_dict = False. The default is true. Hub doesn’t currently handle
dictionaries as outputs automatically. We have this in our backlog. Another workaround in the meantime would be to
write a wrapper module that converts the dictionary to tuple.
My profile job failed with a request feature arch with value [0-9]+ unsupported, what does this mean?
This error is surfaced when the context binary is built for a newer version of the Hexagon architecture than the target device supports. To fix this issue, recompile the source model with the device that will be used for profiling or inference.
My profile job failed, citing an error code 3110. Why did this happen?
This error means that a model cannot be prepared for the device. There are a couple reasons this could occur:
1. Float not supported. Failed for node <name> of type <type> with error code 3110. A 3110 error occurs when the input or output types of a node are not supported by the QNN backend. This is often caused by a node that isn’t properly quantized or an unquantized tensor is passed through, which will result in an error. To fix this issue quantize (or re-quantize) the model. Operator definitions and constraints can be found in the HTP Backend Op Definition Supplement.
Unsupported rank. Many ops support <5D only. some have 5D support, and none have >5D support.
Unsupported type. Many ops don’t support all types. This error is quite common for [u]int32 layers.
My profile job failed with Error code: 1002 at location qnn_model.cc:167 onnxruntime::qnn::QnnModel::FinalizeGraphs, what do I do?
If the Runtime Log does not provide any helpful information, we recommend profiling again with the options: --runtime_debug=true --max_profiler_iterations=1.
With these settings, the Runtime Log will often give additional information on the cause of the issue.
Deployment
Why does my model run slower on my device than in Hub?
In Hub, we attempt to create a realistic environment in which to run models as fast as possible. We assume that developers will most often deploy into an app with a user interface and so our profiler is implemented as such. By default, we run it at the highest available power setting to achieve the fastest possible inference. Let’s look at the consequences of these choices.
Scheduling Priority
Hub’s profiler is an Android application on all supported mobile and automotive devices. This means that it benefits
from preferential scheduling at the kernel level. Android does this by default to provide a responsive user interface.
It does not extend this policy to CLI tools that may be run via adb shell, including qnn-net-run. This
introduces a performance gap between GUI and CLI tools. The impact can be quite substantial. In a trial running
MobileNetV2 on 65 different Android devices, we found an average [3] slowdown of 9.7% using a CLI
version of our profiler compared to the GUI used in production. To run a CLI tool with the same scheduling priority as
a GUI app, use nice -n -10 YOUR_TOOL with root privileges.
Power Settings
By default, Hub will request BURST power settings on all mobile devices. This typically results in substantially faster execution than the default. The steps to enable this in your app depend on the ML framework in use. ONNX Runtime and TensorFlow Lite have settings that will cause them to set this on your behalf. With Qualcomm® AI Engine Direct, it is necessary to set voltage corners and other options individually as outlined in the page linked above.
Profile Settings
Collecting detailed profiling data, (e.g., qnn-net-run --profiling_level detailed) can introduce substantial
overhead. Use these settings only when necessary to compare relative runtimes of network layers.
Other Settings
Settings that AI Hub overrides from framework defaults (including those you specify) can be found in the “Runtime Configuration” settings of inference and profile job pages. Note in particular that fp16_relaxed_precision is enabled by default.
Why am I seeing error 1008 when trying to use HTP?
Error 1008, also known as QNN_COMMON_ERROR_INCOMPATIBLE_BINARIES typically indicates a failure to initialize
the HTP. Most often, this is because libraries containing code that run on the HTP [4] cannot be found. On
most platforms, the environment variable ADSP_LIBRARY_PATH must be set to a directory containing the skel files
corresponding to your device’s DSP architecture [5]. More information can be found in
this QNN tutorial.
It’s still not working; I’m running Windows
There are two additional things to check.
First, the skeleton files should really be in the same directory as QnnHtp.dll. We have seen documentation
suggesting that ADSP_LIBRARY_PATH works as it does on other platforms, but our experience is that it is ignored on
Windows.
Second, Windows also requires that the .cat file distributed alongside skeletons is available: when copying
skeleton libraries to your application’s executable directory, don’t forget the .cat file.
How do I use the HTP on an automotive device?
Using HTP in automotive guest VMs requires an additional step beyond setting ADSP_LIBRARY_PATH as outlined above:
two files must be copied from the QNX host into the guest VM. Specifically, these files must be copied into a directory
in ADSP_LIBRARY_PATH, typically the one containing the appropriate skeleton libraries.
For targets with /dspfw and /dsplib partitions:
/dsplib/image/dsp/cdsp0/libc++.so.1/dsplib/image/dsp/cdsp0/libc++abi.so.1
For targets without /dspfw and /dsplib partitions:
/mnt/etc/images/cdsp0/libc++.so.1/mnt/etc/images/cdsp0/libc++abi.so.1
If you have additional questions that weren’t covered in this, please reach out to us on AI Hub Slack.