How it works
Qualcomm® AI Hub helps optimize, validate, and deploy machine learning models on-device for vision, audio, and speech use cases.
What does Qualcomm® AI Hub measure?
Profile jobs on Qualcomm® AI Hub measure the resources required to run an optimized model on a wide array of physical devices. The metrics it collects are specifically designed to help you determine if a model fits within your time and memory budget.
Overview
Profiles are collected in terms of the four steps required to run a Target Model on a user’s device.
Compilation – On platforms supporting on-device compilation, Hub reports relevant metrics when the system provides a sufficiently stable and resource-respecting toolchain.
First App Load – The first time a model is loaded, the operating system may further optimize the model for the device on which it is running. For example, if a neural processing unit (NPU) such as the Qualcomm® Hexagon™ Processor is available, the model will be prepared for execution on that hardware. The result is typically cached to make subsequent loads faster.
Subsequent App Load – From the second time onwards that a model is loaded, it may avoid costly device-specific on-device optimization.
Inference – After the model has been loaded, Hub performs inference. Profiling jobs prepare random data and execute the model several times in a tight loop.
The time and memory metrics described below are collected for each step.
Time
Many steps can only be sensibly executed once. For example, it is often impossible to clear all framework and OS caches after First App Load. Therefore, only inference is measured more than once.
Over the course of many iterations, Hub measures the clock time required to evaluate the model. The cost includes only the cost of the call to the inference framework and a small amount of overhead.
The inference time measurement is a microbenchmark whose purpose is to isolate the model from other noise so that it can be meaningfully optimized as an atomic unit. Inputs are generated only once per batch and reused for multiple iterations. Hub reports the minimum observed time, which results in a more repeatable metric that excludes noise that would not be reduced by model optimization.
Memory
There are many ways to characterize the memory usage of an app. However, most developers are interested in knowing what the footprint of their app is from the perspective of the operating system. After all, that is what determines if an app is killed or asked to purge memory. As we explain below, even this can be difficult to predict. To provide clear and comprehensive memory metrics, Hub reports ranges, which are more accurate than single-number metrics.
Virtual Memory
Modern operating systems provide a layer of abstraction between a user process and physical memory typically called virtual memory. When a process requests memory, few or no addresses are immediately mapped to physical memory. Instead, the OS performs some internal bookkeeping to note that some range of addresses has been promised and that they are clean.
Memory in the clean state has not been written to so its contents need not be preserved if the system runs low on memory. When a process writes to memory, it becomes dirty, meaning the OS cannot independently discard its contents without data loss. If a piece of dirty memory has not been accessed for some period, the OS might free the associated physical memory by writing the data to disk (swapping) or compressing the memory, making it smaller, but temporarily unusable. The memory footprint of an app is the sum of non-clean memory: dirty, swapped, and compressed.
Most Unix-like operating systems, including Android and Linux, do not guarantee that virtual memory can be mapped to physical storage. If global usage is high, demand may exceed the available physical memory and on-disk swap. When that occurs, the system will attempt to preserve its stability by terminating memory hungry processes. Windows takes a different approach: when a process allocates virtual memory, the system commits to store its contents in physical memory and/or page files, ensuring that global demand never exceeds system capacity. Since the system will never run out of memory, terminating overcommitted processes is unnecessary.
Heap
The OS has to manage an unimaginably large virtual address space on modern devices. The metadata required to maintain mappings of virtual addresses to arbitrarily small allocations would be prohibitive for the kernel. Therefore, systems have a minimum allocation size, a page, which is typically in the range of 4-16 KB. Of course, programs usually create objects that are much smaller than a single page. To make efficient use of memory, malloc is used to pack multiple program objects into one or more OS pages.
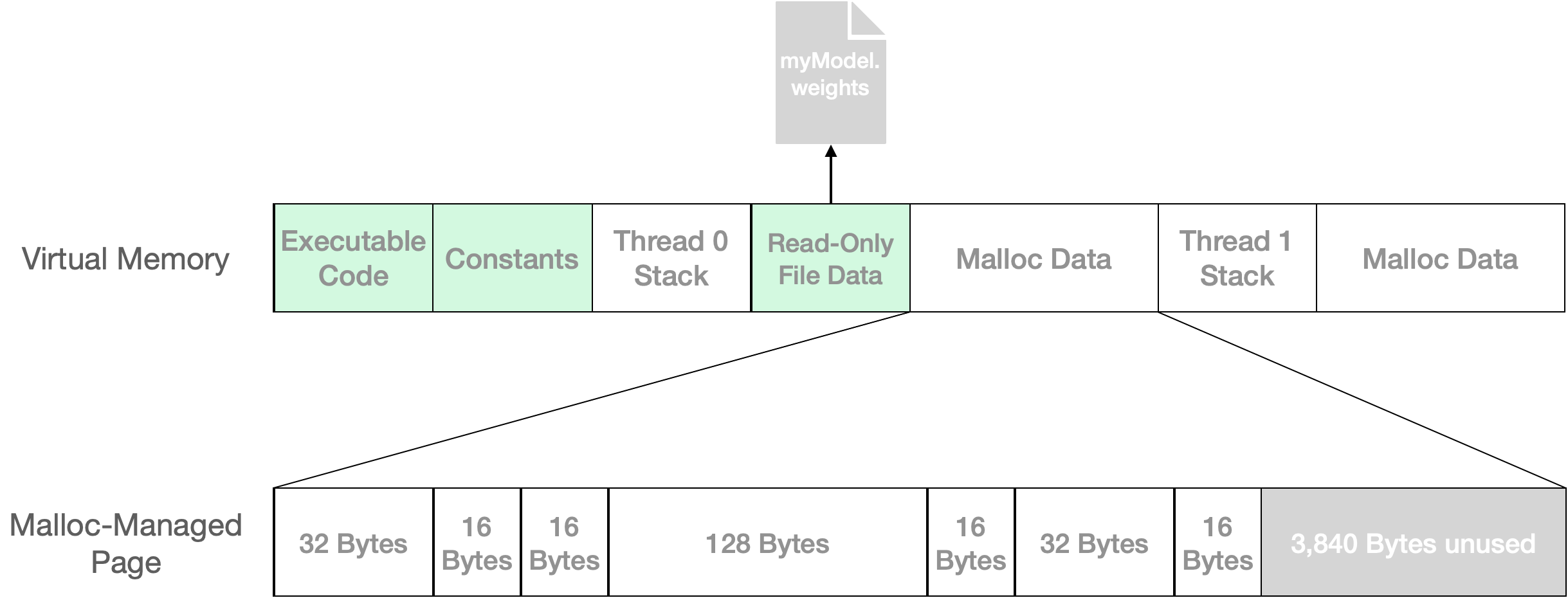
Figure 1: Virtual memory is allocated by the operating systems in units of pages, which may be clean (shown as green) or non-clean. Malloc is an interface to efficiently pack small objects into these large pages. In this example, 256 bytes of user data are packed into a single 4,096 byte page, leaving 3,840 bytes available for future calls to malloc.
Figure 1 shows a simplified virtual memory address space. Clean regions are those that the OS can recreate without running any user code. This is typically because these pages are backed by an unchanging file or simply have not been written to. From some operating systems’ perspectives, non-clean pages constitute an application’s memory footprint: if your app has too many dirty, swapped, and/or compressed pages, it is at risk for termination if the system runs low on memory.
Most runtime data is managed by malloc, whose dirty pages may be only partially utilized. In this example, 256 bytes of user data are held in a 4 KB page, but 3,840 bytes are unused. In real applications, memory hungry tasks such as model compilation and loading can leave considerable amounts of this unused space in malloc-managed pages. This memory can typically be reused by subsequent steps.
In computing a memory footprint, OS-provided tools and APIs are unaware of how much of malloc-managed pages are unused. Since some or all of this unused memory may be reused, on Android, Hub reports memory usage as a range that assumes complete reuse in the best case and none in the worst.
As noted above, the situation is different on Windows. Since it is impossible for the system to unexpectedly run out of memory, there is no memory monitor that might terminate a user’s process. Therefore, on Windows, Hub’s memory usage metrics assume that no already-allocated heap space will be reused by subsequent demands. Both ends of the reported range are the process commit charge, which is the sum of virtual memory allocations. Additional metrics including working set size can be found in the runtime log file.
Peak vs Increase
The memory used to complete a task typically exceeds the size of the result. Consider a scenario where we are compiling a model; assuming no memory leaks in the compiler, it will take some amount of memory to translate an on-device model to a compiled model, leaving an artifact on disk and no objects in memory. If the compiler took 40 MB, we would say that its peak usage was 40 MB, but the steady state increase of memory usage was 0 bytes.
Specific Memory Metrics
Putting it all together, a profiling job will return memory metrics similar to those shown in Table 1. The source of the CNN model in the example is 54 MB and so it is not surprising to see that about 163 MB are used during on-device compilation, but that no memory is used after the compiled model is persisted to disk. The upper bound of the increase reports a worst case scenario, that none of the 0.7 MB of unused malloc-managed memory left after compilation will ever be reused by the app. Similarly, the amount of data held by the app after loading the model likely does not actually differ between first and subsequent loads, though the initial load left more unused malloc-managed memory. This is not unexpected since the initial load likely did more work and therefore more allocations.
Stage |
Peak |
Increase |
|---|---|---|
Compilation |
162.7 - 163.4 MB |
0.0 - 0.7 MB |
First App Load |
1.7 - 2.8 MB |
0.6 - 1.7 MB |
Subsequent App Load |
1.8 - 2.5 MB |
0.8 - 1.6 MB |
Inference |
629.6 - 630.6 MB |
378.7 - 379.6 MB |
In Hub, we present the peak range, which highlights the most important contributions your model makes to memory pressure, which may cause the OS to terminate your app. Those and all other metrics are available in the Python client library. The complete set of memory and timing metrics is shown in Table 2.
Key |
Type |
Units |
|---|---|---|
|
|
Bytes |
|
|
Bytes |
|
|
Bytes |
|
|
Bytes |
|
|
Bytes |
|
|
Bytes |
|
|
Bytes |
|
|
Bytes |
|
|
Microseconds |
|
|
Microseconds |
|
|
Microseconds |
|
|
Microseconds |