よくある質問
このドキュメントは、Qualcomm® AI Hub でよくある質問やジョブの失敗理由の回答を目的としています。参考としてご利用いただき、AI Hub Slack で気軽に質問してください。
一般
AI Hubに提出されたモデルは実際のデバイスで動作しますか?
はい、私たちは複数のデバイスファームを通じて数千の実際のデバイスをホストしています。AI Hubを使用して特定のデバイスでモデルを実行するとき、デバイスを取得し、OSとモデルを実行するために必要なすべてのフレームワークをインストールします。その後、AI Hubで提示されるすべてのメトリクスを捉えるためにそのデバイスでモデルを実行します。このプロセスが完了すると、デバイスを解放します。AI Hubに提出されたすべてのジョブに対してこのプロセスを繰り返します。利用可能なすべてのデバイスを確認するには、qai-hub list-devicesを実行してください。
AI Hubでのデバイスプロビジョニングはどのように機能しますか?多くのユーザーが同時に異なるデバイスでモデルを実行できますか?
はい。多くのデバイスがあり、すべてのデバイスでモデルを並行して実行できます。実際のデバイスが取得されると、そのデバイスには特定のモデルのみが実行されます。
はい、ユーザーがジョブを提出すると、各ジョブに対して別々のデバイスが取得され、正確なメトリクスが提供されます。
AI Hubでジョブを送信するためのどのようにAPIトークンを設定すればよいですか?
Qualcomm MyAccountを作成したら、Qualcomm® AI Hub にログインし、設定ページに移動してユニークなAPIトークンを取得します。詳細な手順については、このトピックに関する ハウツービデオ を見ることをお勧めします。
AI Hubで自分のジョブをチームメンバーや他のチームメンバーに表示させるにはどうすればよいですか?
- AI Hubのジョブは自動的に組織と共有できます。チームの開発者を組織に追加したい場合は、
AI Hubアカウントを持っている開発者のメールアドレスを ai-hub-support@qti.qualcomm.com にメールしてください。
AI Hubジョブはサポートを得るために組織外またはQualcommと共有することもできます。ジョブの右上にある「Share」ボタンをクリックし、AI Hubユーザーのメールアドレスを指定すると、ジョブ(および関連するモデルアセット)が共有されます。メールアドレスをジョブから削除することでアクセスを取り消すこともできます。
AI Hubで最適化済みモデルはどこで見つけられますか?
以下の場所のいずれかにアクセスして、AI Hubで事前に最適化されたモデルを見つけることができます。現在150以上の最適化済みモデルが利用可能で、常に新しいモデルを追加しています。
Qualcomm® AI Hub Models, Qualcomm's Hugging Face, Qualcomm® AI Hub Models
自分のモデルを持ち込んでAI Hubで実行できますか?
はい。この機能は誰でも使用できます。ただし、成功するモデルには既知の制限があることに注意ください。モデルがコンパイルに失敗する理由は次のとおりです:
モデルが大きい(例:> 2GB)。
モデルがPyTorchでトレースに失敗する可能性があります。エラーメッセージに従ってモデルを変更してください:
モデルにブランチ(if/else)がある場合、
torch.jit.trace中にcheck_trace=Falseを設定すると問題が解決します。
LLM/GenAIモデルはすぐには動作しない可能性があります:
これらの大規模なモデルは、デバイス上で効果的に動作するために量子化が必要な場合があります。ガイダンスについては、LLMレシピを参照してください。
その他の変換問題:
変換が内部で失敗することがあります。不明なエラーメッセージ(例:内部デバイスエラー)が表示された場合はお知らせください。問題を迅速に調査するために最善を尽くします。サポートされるモデルは常に増え続けています!
コンパイルジョブが失敗した場合、提供された入力仕様がモデルと互換性があることを確認してください。
AI Hubで最初のジョブを送信するには、このトピックに関する ハウツービデオ を見ることをお勧めします。問題が発生した場合は、AI Hub Slack でお問い合わせください!
Qualcomm AI Hub ModelsにないHuggingFaceのモデルを試すことはできますか?
はい!これらは試すのに最適なモデルです。使用ケースに適したモデルがリストにない場合は、https://huggingface.co/models をチェックしてモデルを選択してください。その後、必要なパッケージをインポートし、コンパイルジョブを送信する前にモデルをトレースできます。(ジョブを送信する際の一般的なエラーについては、以下を参照してください。)
AI Hubで量子化モデルを実際のデバイスで実行できますか?
はい。Qualcomm® AI Hub Models にはいくつかの量子化モデルがリストされており、モデルの精度セクションでフィルタリングしてパフォーマンスを確認できます。これらは AIMET で量子化されていますが、量子化 を使用するように移行中です。
独自の量子化モデルを持ち込みたい場合は、量子化 を使用して量子化することをお勧めします。これは、非量子化されたONNXを取り込み、出力として量子化します。
Qualcomm® AI Hubで特定のデバイスでモデルを実行するにはどうすればよいですか?
モデルを送信する際に、ターゲットとするデバイスを指定する必要があります。利用可能なデバイスのリストを取得するには、qai-hub list-devices を実行します。そこから、名前または属性のいずれかでデバイスを指定できます。例えば、device = hub.Device(attributes="qualcomm-snapdragon-845") は845チップを持つ任意のデバイスで実行されますが、device=hub.Device("QCS6490 (Proxy)") は6490プロキシデバイスで特定に実行されます。また、デバイスファミリーもあり、該当する場合リストのデバイスの横に表示されます。例:Google Pixel 3aファミリー、Samsung Galaxy S21ファミリーなど。これはデバイスプロビジョニング時間を短縮し、特定の名前を持つデバイスの長いキュー時間を軽減するのに役立ちます。指定したチップセットを持つデバイスが常に提供されます。このオプションを適用する場合は使用してください!このトピックに関する ハウツービデオ を見ることをお勧めします。
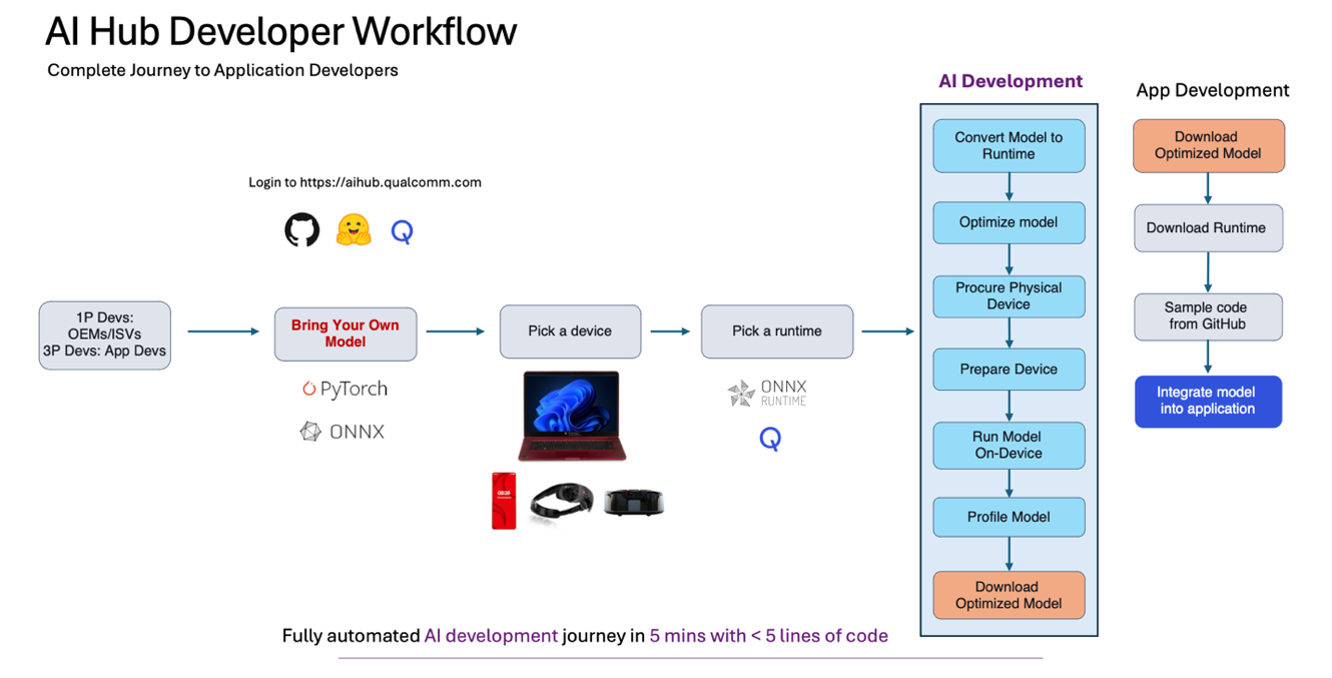
AI Hubを使用する際の典型的な開発者のワークフローは何ですか?
ステップ1:使用ケースに適したモデルを選択します。Qualcomm® AI Hub Models から選ぶか、独自のモデルを持ち込みます。
ステップ2:学習済みモデル(PyTorch、ONNX、AIMET量子化モデル)を指定されたデバイス用にコンパイルするためにコンパイルジョブを送信します(利用可能なデバイスを確認するにはqai-hub list-devicesを使用します)および desired target runtime。
ステップ3:クラウドにホストされている実際のデバイスでコンパイル済みモデルを実行し、パフォーマンスを分析するためにプロファイルジョブを送信します(例:レイテンシ目標、メモリ制限、希望する計算ユニットで実行されているかどうか)。ここで、モデルのパフォーマンスに関する豊富なメトリクス, レイヤーごとのタイミング、各レイヤーの可視化、読み込みおよび推論時間、ジョブが失敗した場合に重要なランタイムログ情報などを取得できます。
ステップ4:入力データをアップロードし、実際のデバイスで推論を実行し、出力結果をダウンロードするために推論ジョブを送信します。
ステップ5:オンデバイス出力に対して必要な後処理計算を行い、モデルの精度を確認します。
ステップ6: 最適化済みモデルをプログラムでダウンロードし、アプリケーションに統合します。モデルをアプリケーションに統合する際の参考として、 サンプルアプリ をご覧ください。
推論ジョブとプロファイルジョブでモデルのレイテンシーが異なるのはなぜですか?
プロファイルジョブを提出すると、指定されたデバイスで推論が100回行われます。これは、アプリケーションに組み込む際にどれくらいの時間がかかるかを正確に示すためです。最初のサイクルは通常、起動時間やキャッシュのウォームアップなどの理由で最も遅くなります。プロファイルジョブ中に推論が行われる回数は、max_profiler_iterations オプションでカスタマイズできます。しかし、推論ジョブは指定されたデバイスで1回だけ実行され、その主な目的は精度計算を行い、モデルが数値的に同等であり、ダウンロードして展開する準備ができていることを確認することです。
AI Hubを使用してモデルを実行し、最適化済みモデルをダウンロードしました。次は何をすればよいですか?
良い質問です!次のステップは、モデルアセットをアプリにバンドルし、ターゲットエッジデバイス(モバイル、IOT、コンピュートなど)に展開することです。これを行う方法についての サンプルアプリ がいくつかあり、さらに提供するために取り組んでいます。特に Qualcomm® AI Engine Direct を使用する場合の .bin ファイルの統合については、これらのドキュメント をチェックしてください。私たちは、このトピックに関するサンプルアプリや情報を追加するために積極的に取り組んでいます。Rb3Gen2に展開するIOT顧客向けには、AI Hubからの最適化済みモデルと一緒にFoundries.ioを活用することをお勧めします。
AI Hubに公開されているモデルのライセンス条件は何ですか?これらのモデルをアプリに使用してユーザーにリリースできますか?
AI Hub Modelsは、事前に最適化されたオープンソースモデルのコレクションを紹介しています。各モデルのライセンスは、対応するモデルページに記載されています。
独自のモデルを持ち込んだ場合のライセンス条件はどうなりますか?これはQualcommの知的財産になりますか?
AI Hubはデバイス用にモデルを最適化するためのプラットフォームです。"独自のモデルを持ち込む" 場合、AI Hubから得られるデプロイされたアセットは通常、モデルと同じ配布ライセンスを持ちます。それが独自の知的財産である場合、モデルはあなたのものとして配布できます。詳細は利用規約の一部として見つけることができます。
AI HubまたはAI Hub Modelsを本番アプリケーションで使用する場合、またはモデルテストのためにAI Hubに統合する場合に料金が発生しますか?
AI Hub、私たちのプラットフォームは現在完全に無料で使用できます。モデルを送信し、コンパイルし、パフォーマンスをプロファイルして反復し、推論ジョブを送信して精度を確認し、アプリにバンドルするためのターゲットアセットをダウンロードすることをお勧めします。
私たちのモデルコレクションには、ライセンスに基づいて購入が必要な特定のモデルが含まれています。詳細についてはお問い合わせください。aihub.qualcomm.comで 'download now' と表示されているモデルは無料で使用できます。モデルページに記載されているライセンスを確認し、それに従って使用してください。
AI Hubがクラウドでモデルを実行している場合、それは安全ですか?アップロードしたモデルを他のユーザーが見ることができますか?
AI Hubを使用して行うすべての操作は、他のユーザーと明示的に共有しない限り、プライベートかつ安全に保護されます。これには、アップロードされたすべてのデータセットとモデル、AI Hubジョブを通じて作成されたモデル、データセット、メトリクスが含まれます。ジョブ完了後、物理デバイスやその他のクラウドコンピューティング環境の一時ストレージから顧客の成果物は消去されます。他のユーザーがあなたの個人情報を見ることはできません。
Qualcommがデータを収集・使用する方法についての詳細は、Qualcomm privacy policy をご参照ください。ご不明な点がございましたら、email us までご連絡ください。
チームメンバーを組織に追加するにはどうすればよいですか?
各ユーザーには独自の組織があり、ユーザーのモデルとデータはその組織内で安全に保管され、アクセスはユーザー自身と組織に追加された人々に限定されます。AI Hubで組織に誰かを追加したい場合はお知らせください。そうすれば、彼らはあなたのジョブを見たり、逆も可能です。
特定のジョブに誰かを追加したい場合は、ジョブの右上にある共有ボタンを使用してそのメールアドレスを追加することをお勧めします。
AI Hubの変更点はどのようにわかりますか?
リリースノートを AI Hub Slack に投稿しています!また、ドキュメント でも見つけることができます。
モデル形式
なぜ Qualcomm® AI Hub Models は一部のモデルに対して TensorFlow Lite の結果のみを提供するのですか?
事前に最適化された100以上のモデルのコレクションを見ると、モデルに応じて TensorFlow Lite または Qualcomm® AI Engine Direct の結果のみが表示される場合があります。両方のパスのパフォーマンス結果を提供するために取り組んでおり、その場合、TorchScript → TensorFlow Lite および TorchScript → Qualcomm® AI Engine Direct のドロップダウンが表示され、表示したいパフォーマンス数値を選択できます。さらに、 Compute Models を見ると、該当する場合、TorchScript → ONNX Runtime のパフォーマンス結果も表示されます。
どのパスをお勧めしますか?TensorFlow Lite、ONNX Runtime、または Qualcomm® AI Engine Direct?
モデルによっては、あるパスが他のパスよりも高速である既知の問題があります。私たちの継続的な目標は、これらの問題を追跡し、パス全体で解決することです。ほとんどのモデルでは、最適化するにつれて、ほぼ同じパフォーマンスを期待できます。最終的には、すべてのパスが同じQNNおよび同じハードウェアに導かれるため、基本的に異なることは何もありません。TensorFlow Lite は TensorFlow Lite Delegateを介してHexagon NPUにアクセスし、ONNX Runtime は ONNX 実行プロバイダーを介してHexagon NPUにアクセスし、Qualcomm® AI Engine Direct はもちろんHexagon NPUを活用します。
モバイルデバイスにデプロイするAndroid開発者には TensorFlow Lite、ラップトップにデプロイするWindows開発者には ONNX Runtime、およびSOC/オペレーティングシステムに応じて Qualcomm® AI Engine Direct をお勧めします。異なるランタイムを試し、ターゲットデバイスに最適なパフォーマンスを提供するパスを使用することを強くお勧めします。
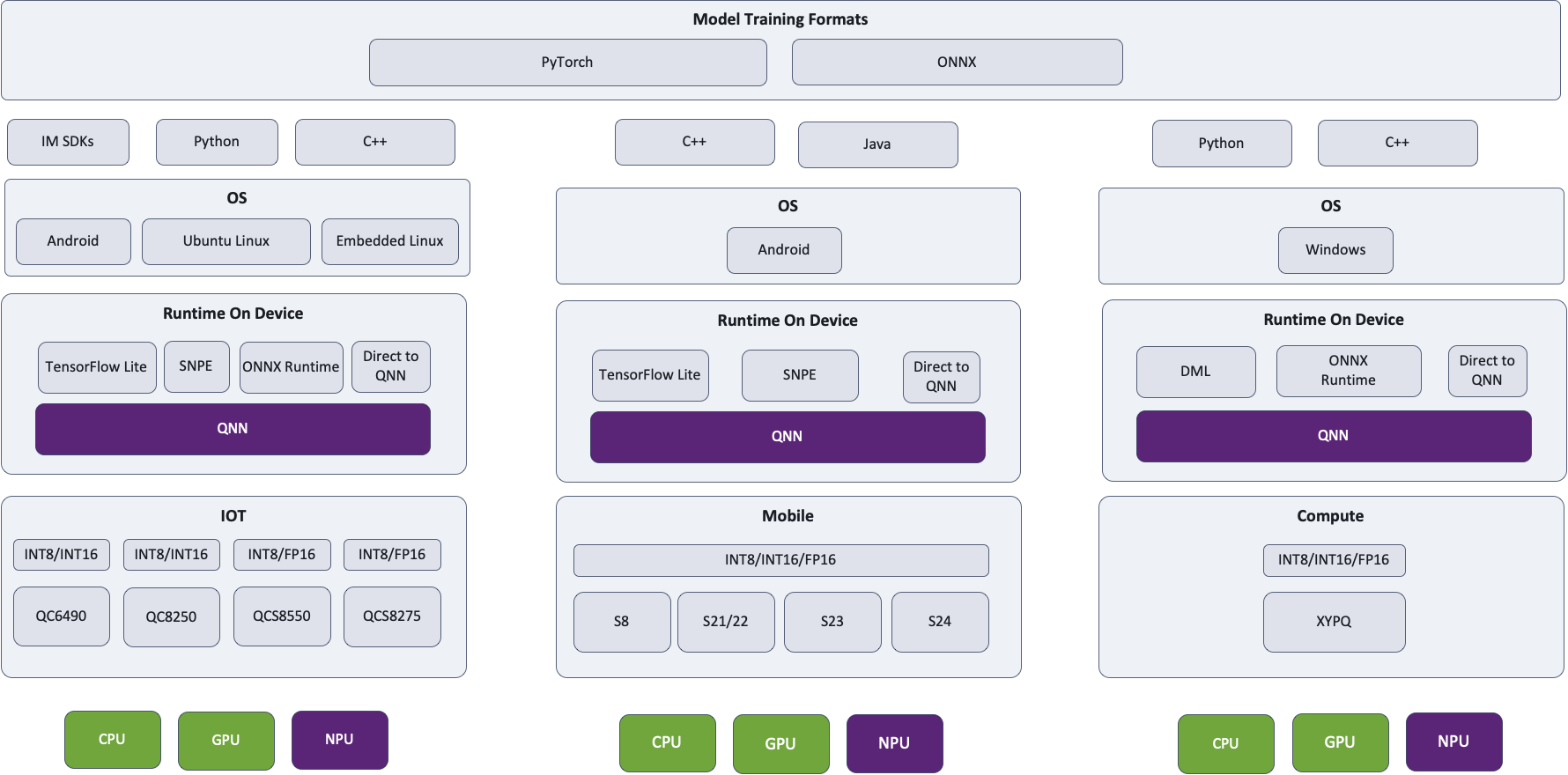
ここでは、選択されたパスおよび指定されたランタイムに関係なく、QNNが使用され、該当する場合はHexagon NPUが活用されるアーキテクチャ図を示します。Hubは常に最適な計算ユニットでモデルを実行します。
どの Qualcomm® AI Engine Direct モデル形式を使用すべきですか?
Qualcomm® AI Engine Direct SDKは、オンデバイス実行のために3つの形式をサポートしています:モデルライブラリ(.so および .dll)、コンテキストバイナリ(.bin)、およびディープラーニングコンテナ(.dlc)。これらの間には、ランタイムパフォーマンスに影響を与える可能性のある重要な違いがあります。
モデルライブラリ(
--target_runtime qnn_lib_aarch64_android)は、単一の関数をエクスポートする動的ライブラリです。これを呼び出すと、QNNグラフ構築関数を使用してモデルがインスタンス化されます。この形式はOS固有ですが、最終的なグラフは実行されるデバイスに最適化され、最適な推論パフォーマンスを確保します。ディープラーニングコンテナ(DLC)は、モデルライブラリと同様に、ネットワークのSoCに依存しない表現を含みます。特定のターゲットSoCセットのためのコンテキストバイナリを追加で埋め込むことができますが、これはまだ一般的に使用されていません。通常、このOSに依存しない形式は、デバイス固有の最適化の前にQNNレベルのグラフデータ構造の構築を駆動するために使用されます。
コンテキストバイナリは、OSに依存しないHTP固有の表現です。これは、モデルライブラリをロードし、特定のSoC用にグラフを準備し(つまり、特定のHTP用にHexagonコンパイラを呼び出すことを可能にし)、結果のデータ構造を保存することに相当します。HexagonコンパイラはHTPの使用を前提とするため、コンテキストバイナリは特定のHTPをターゲットにした場合にのみ最適なパフォーマンスを達成します。古いデバイス用にビルドされたバイナリを新しいチップで使用することは可能ですが、パフォーマンスが低下する可能性があります。
最適なパフォーマンスを達成するために、
qnn-context-binary-generatorに正しいsoc_modelを指定してください。正しい値は、Qualcomm® AI Engine Direct の Overview にあるサポートされているSnapdragonデバイスの表を参照することで見つけることができます。また、SDKのdocs/QNN/index.htmlにあり、Overviewリンクをたどることでも確認できます。また、Qualcomm® AI Hub ランタイムログの上部近くに、Qualcomm® SoCをターゲットにしたデバイスに関する情報が記載されています。
Qualcomm® AI Engine Direct モデル形式の概要
形式 |
バックエンド |
OSに依存しない |
SoCに依存しない |
読み込み時間 |
推論パフォーマンス |
|---|---|---|---|---|---|
ライブラリ |
任意 |
いいえ |
はい |
長い |
最適 |
DLC |
任意 |
はい |
はい |
長い [1] |
最適 |
コンテキストバイナリ |
HTP |
はい |
いいえ |
最速 |
最適 [2] |
プロキシデバイスから実際のハードウェアにアセットをデプロイできますか?
要約 -- TensorFlow Lite および ONNX Runtime アセットは問題ありませんが、QNNモデル形式には問題があるかもしれません。
過去には、プロキシデバイスがAI Hubに追加され、AI Hubがサポートしていない人気のあるデバイスと同様のパフォーマンス特性を持つSoCを持つデバイスへのプロファイリングおよび推論アクセスを提供する方法として使用されていました。例えば、RB3 Gen 2に見られるQCS6490は、いくつかのモバイルデバイスに見られるSM7325と本質的に同じチップです。これはベンチマークや精度評価に非常に役立ちますが、QNNモデル形式を生成する際に課題が生じることがあります:
モデルライブラリはOS固有です。プロキシは通常Androidを実行しますが、実際のデバイスはLinuxを使用するかもしれません。
コンテキストバイナリはSoC固有です。プロキシデバイスをターゲットにすることで実際のデバイスで良好なパフォーマンスが得られると期待していますが、これは文書化された保証ではありません。
場合によっては、まったく異なるQNN SDKのフレーバーが使用されます。例えば、すべての自動車用プロキシデバイスはモバイルデバイスですが、すべてのCockpit、ADAS、およびFlexデバイスは、同じ世代の自動車用およびモバイルチップの違い(例:SA8295PのV68 HTPでのfp16サポート)を認識している特定の自動車用SDKの使用を必要とします。
幸いなことに、サードパーティのフレームワークは読み込み時に最適化を行うことでこれらの問題をすべて回避し、TensorFlow Lite および ONNX Runtime アセットをこの状況でデプロイするのに適した選択肢にします。
オプションの受け渡し
計算ユニットをどのように指定すればよいですか?
AI Hubで任意のタイプのジョブを送信する際に、オプション --compute_unit <units> を使用して、モデルを実行する計算ユニットを指定します。複数の計算ユニットを指定したい場合は、カンマで区切ります。例: --compute_unit npu,cpu。このトピックに関する ハウツービデオ を見ることをお勧めします。
ターゲットランタイムをどのように指定すればよいですか?
Qualcomm® AI Hub は、TensorFlow Lite、ONNX Runtime、および Qualcomm® AI Engine Direct (コンテキストバイナリおよびモデルライブラリ)をターゲットランタイムとしてサポートしています。コンパイルジョブを送信する際に、オプション --target_runtime <runtime> を使用してランタイムを指定します。このトピックに関する ハウツービデオ を見ることをお勧めします。
NPUを活用していることをどのように確認すればよいですか?
各ターゲットランタイムには、利用可能なハードウェアを最大限に活用するための独自の戦略があります。パフォーマンスと機能のトレードオフがあります:NPUは最高のパフォーマンスを提供する傾向がありますが、計算できるものが最も制限されています。逆に、CPUはニューラルネットワーク推論に最適化されていませんが、任意の操作を実行できます。複数のハードウェアバックエンドをサポートするランタイムは、GPUまたはCPUにフォールバックする前に可能な限り多くのネットワークをNPUで実行します。
NPUの使用を有効にするには、ランタイムを(1)それを使用するように構成し、(2)ネットワークがサポートされていない操作やパラメータを使用しないようにする必要があります。
デフォルトでは、AI Hubはフォールバックをサポートするランタイムを構成して、GPUおよび/またはCPUに低下させる前にNPUを採用します。NPUの使用を 必須 にするには、コンパイル/ランタイムオプション --compute_unit npu を指定します。また、qnn_lib_aarch64_android などのQNNターゲットランタイムを使用することを検討してください。
NPUからレイヤーが外れる一般的な理由には、未対応のopや未対応のランク(rank)が含まれます。特に、ランクが ≥ 5の場合はサポートが制限されることがあります。このような状況が、異種ディスパッチをサポートするランタイム(例:TensorFlow Lite)で発生した場合、これらのレイヤーは単純にGPUまたはCPUにフォールバックされるべきです。場合によっては、ネットワーク全体がNPUから外れることもあります。これは、デバイス上でネットワークを準備する際に予期しないエラーが発生した場合に起こる可能性があります。そのような場合、ネットワークはGPUまたはCPU上で実行されます。このような事象が発生した場合は、AI Hub Slack にご連絡ください。こちらでジョブの確認をさせていただきます。
最適化オプションをどのように指定すればよいですか?
デフォルトでは、AI Hubは常にランタイムパフォーマンスのためにモデルを最適化します。時折、これが問題になることがあります。大規模なモデルは、Hexagonコンパイラが単に多くの作業を行うため、ジョブがタイムアウトする原因となることがあります。まれに、より高い最適化レベルが悪いコードを生成することがあります。そのような場合、最適化レベルを下げることが理にかなっているかもしれません。方法はターゲットランタイム環境によって異なります。
NPUをターゲットにした Qualcomm® AI Engine Direct の場合(例:
--target_runtime=qnn_lib_aarch64_android --compute_unit all)、--qnn_options=default_graph_htp_optimization_value=xを使用します。ここで、xは1または2です。Hexagonコンパイルはqnn_lib_*を使用して デバイス上 で行われますが、qnn_context_binaryをターゲットにする場合はモデル変換中に事前に実行されることに留意ください。NPUへの委任が成功した Qualcomm® AI Engine Direct に委任する TensorFlow Lite の場合(例:
--target_runtime=tflite)、--tflite_options=kHtpOptimizeForPrepareを使用します。これにより、QNN最適化レベルが1に設定されます。tfliteをターゲットにする場合、Hexagonコンパイルは常にデバイス上で行われます。
一般的なジョブの失敗と既知の問題
コンパイルジョブがopが欠落しているというエラーメッセージで失敗しました。どうすればよいですか?
ONNXからTensorflowへの変換中にエラーが発生しました:Op 'xx' はまだ実装されていません というエラーが発生した場合は、AI Hub Slack でお問い合わせください。opサポートの追加を優先することができるかもしれません(またはすでに進行中かもしれません)。そうでない場合、適用可能な場合は回避策を提供することができます。
ドキュメントに記載されているオプションを渡したにもかかわらずジョブが失敗しました。どうすればよいですか?
正しいジョブタイプ(例:コンパイル対プロファイル)にオプションを渡していることを確認してください。例えば、--quantize_full_type はコンパイルジョブオプションです。プロファイルジョブに渡すと失敗します。それでも問題が発生する場合は、AI Hub Slack でお問い合わせください。
Hugging Faceからのモデルが "DictConstruct" がサポートされていないために失敗しました。どうすればよいですか?
model.config.return_dict = False を設定することをお勧めします。デフォルトは true です。Hubは現在、ディクショナリを自動的に出力として処理していません。これをバックログに追加しています。その間の別の回避策として、ディクショナリをタプルに変換するラッパーモジュールを作成することができます。
プロファイルジョブが「request feature arch with value [0-9]+ unsupported」というエラーで失敗しました。これは何を意味しますか?
このエラーは、コンテキストバイナリがターゲットデバイスがサポートするHexagonアーキテクチャの新しいバージョン用にビルドされた場合に表示されます。この問題を修正するには、プロファイリングまたは推論に使用されるデバイスでソースモデルを再コンパイルしてください。
プロファイルジョブがエラーコード3110で失敗しました。なぜですか?
このエラーは、モデルがデバイス用に準備できないことを意味します。これが発生する理由はいくつかあります:
Floatがサポートされていません。ノードのタイプでエラーコード3110で失敗しました。3110エラーは、ノードの入力または出力タイプがQNNバックエンドでサポートされていない場合に発生します。これは、適切に量子化されていないノードや、量子化されていないテンソルが通過する場合に発生し、エラーが発生します。この問題を修正するには、モデルを量子化(または再量子化)してください。オペレーター定義と制約は HTP Backend Op Definition Supplement で見つけることができます。
サポートされていないrankです。多くのopsは<5Dのみをサポートしています。一部は5Dをサポートしていますが、>5Dをサポートしているものはありません。
サポートされていないタイプ。多くのopsはすべてのタイプをサポートしていません。このエラーは[u]int32レイヤーで非常に一般的です。
プロファイルジョブが失敗しました。エラーコード: 1002 at location qnn_model.cc:167 onnxruntime::qnn::QnnModel::FinalizeGraphs。どうすればよいですか?
ランタイムログに有益な情報が含まれていない場合は、以下のオプションを使用して再度プロファイルすることを推奨します: --runtime_debug=true --max_profiler_iterations=1。これらの設定により、ランタイムログが問題の原因に関する追加情報を提供することがあります。
デプロイメント
なぜ私のモデルはHubよりもデバイス上で遅く動作するのですか?
Hubでは、モデルをできるだけ早く実行するための現実的な環境を作成しようとしています。開発者がユーザーインターフェースを持つアプリに最も頻繁にデプロイすることを前提としているため、プロファイラはそのように実装されています。デフォルトでは、可能な限り最高の電力設定で実行し、最速の推論を実現します。これらの選択の結果を見てみましょう。
スケジューリングの優先順位
Hubのプロファイラは、すべてのサポートされているモバイルおよび自動車デバイス上のAndroidアプリケーションです。これは、カーネルレベルで優先的なスケジューリングの恩恵を受けることを意味します。Androidは、応答性の高いユーザーインターフェースを提供するために、デフォルトでこれを行います。これには、adb shell を介して実行される可能性のあるCLIツール, qnn-net-run を含む, にはこのポリシーが適用されません。これにより、GUIツールとCLIツールの間にパフォーマンスのギャップが生じます。65台の異なるAndroidデバイスでMobileNetV2を実行する試験では、CLIバージョンのプロファイラを使用した場合、実際のGUIを使用した場合と比較して 平均 [3] 9.7%の遅延が見られました。GUIアプリと同じスケジューリング優先度でCLIツールを実行するには、ルート権限で nice -n -10 YOUR_TOOL を使用します。
電源設定
デフォルトでは、Hubはすべてのモバイルデバイスで BURST 電源設定を要求します。これにより、通常の設定よりも実行速度が大幅に向上します。アプリでこれを有効にする手順は、使用するMLフレームワークによって異なります。 ONNX Runtime および TensorFlow Lite には、これを代わりに設定するオプションがあります。Qualcomm® AI Engine Direct の場合、上記のページに記載されているように、電圧コーナーやその他のオプションを個別に設定する必要があります。
プロファイル設定
詳細なプロファイリングデータを収集すること(例:qnn-net-run --profiling_level detailed)は、かなりのオーバーヘッドを引き起こす可能性があります。ネットワークレイヤーの相対的なランタイムを比較する必要がある場合にのみ、これらの設定を使用してください。
その他の設定
AI Hubがフレームワークのデフォルトからオーバーライドする設定(指定したものを含む)は、推論およびプロファイルジョブページの "Runtime Configuration" 設定にあります。特に fp16_relaxed_precision がデフォルトで有効になっていることに注意してください。
HTPを使用しようとするとエラー 1008 が表示されるのはなぜですか?
エラー 1008 、別名 QNN_COMMON_ERROR_INCOMPATIBLE_BINARIES は、通常、HTPの初期化に失敗したことを示します。ほとんどの場合、HTP [4] 上で実行されるコードを含むライブラリが見つからないためです。ほとんどのプラットフォームでは、環境変数 ADSP_LIBRARY_PATH をデバイスのDSPアーキテクチャ [5] に対応するスケルファイルを含むディレクトリに設定する必要があります。詳細については、 このQNNチュートリアル をご覧ください。
それでも動作しません。私はWindowsを使用しています
確認すべき追加の事項が2つあります。
まず、スケルトンファイルは QnnHtp.dll と同じディレクトリにある必要があります。他のプラットフォームと同様に ADSP_LIBRARY_PATH が機能することを示唆するドキュメントを見たことがありますが、私たちの経験では、Windowsでは無視されることが多いです。
次に、Windowsでは、スケルトンと一緒に配布される .cat ファイルが利用可能である必要があります。スケルトンライブラリをアプリケーションの実行可能ディレクトリにコピーする際に、.cat ファイルを忘れないでください。
自動車デバイスでHTPを使用するにはどうすればよいですか?
自動車用ゲストVMでHTPを使用するには、上記のように ADSP_LIBRARY_PATH を設定する以外に追加の手順が必要です。具体的には、これらのファイルは QNNホストからゲストVMの ADSP_LIBRARY_PATH 内のディレクトリにコピーする必要があります。通常、適切なスケルトンライブラリを含むディレクトリです。
/dspfw および /dsplib パーティションを持つターゲットの場合:
/dsplib/image/dsp/cdsp0/libc++.so.1/dsplib/image/dsp/cdsp0/libc++abi.so.1
/dspfw および /dsplib パーティションがないターゲットの場合:
/mnt/etc/images/cdsp0/libc++.so.1/mnt/etc/images/cdsp0/libc++abi.so.1
この内容でカバーされていない追加の質問がある場合は、AI Hub Slack にお問い合わせください。