動作の仕組み
Qualcomm® AI Hub は、ビジョン、オーディオ、および音声のユースケースにおいて、オンデバイスの機械学習モデルを最適化、検証、およびデプロイするのに役立ちます。
Qualcomm® AI Hub は何を測定しますか?
Qualcomm® AI Hub のプロファイルジョブは、最適化済みモデルをさまざまな物理デバイスで実行するために必要なリソースを測定します。収集されたメトリクスは、モデルが時間とメモリの予算内に収まるかどうかを判断するのに役立つように設計されています
概要
プロファイルは、ユーザーのデバイスでターゲットモデルを実行するために必要な4つのステップに基づいて収集されます。
コンパイル -- オンデバイスコンパイルをサポートするプラットフォームでは、システムが十分に安定し、resource-respectingツールチェーンを提供する場合に、Hubは関連するメトリクスを報告します。
最初のアプリロ ード -- モデルが初めてロードされると、オペレーティングシステムは実行されるデバイスに対してモデルをさらに最適化する場合があります。たとえば、Qualcomm® Hexagon™ プロセッサのようなニューラルプロセッシングユニット(NPU)が利用可能な場合、モデルはそのハードウェアでの実行に備えられます。結果は通常キャッシュされ、次回以降のロードが速くなります。
次回以降のアプリロード -- モデルが2回目以降にロードされると、デバイス固有のオンデバイス最適化を回避できる場合があります。
推論 -- モデルがロードされた後、Hubは推論を実行します。プロファイルジョブはランダムデータを準備し、モデルをタイトなループで複数回実行します。
以下に説明する時間とメモリのメトリクスは、各ステップで収集されます。
時間
多くのステップは一度しか実行できません。たとえば、最初のアプリロード 後にすべてのフレームワークとOSキャッシュをクリアすることはほとんど不可能です。したがって、推論のみが複数回測定されます
多くの反復の過程で、Hubはモデルを評価するために必要なクロック時間を測定します。コストには推論フレームワークへの呼び出しのコストと少量のオーバーヘッドのみが含まれます。
推論時間の測定は、モデルを他のノイズから分離し、アトミック単位として意味のある最適化を行うためのマイクロベンチマークです。入力はバッチごとに一度だけ生成され、複数の反復で再利用されます。Hubは最小観測時間を報告し、モデルの最適化によって減少しないノイズを除外することで、より再現性のあるメトリクスを提供します。
メモリ
アプリのメモリ使用量を特徴付ける方法は多くありますが、ほとんどの開発者はオペレーティングシステムの観点からアプリのフットプリントを知りたいと考えています。結局のところ、それがアプリが終了されるかメモリを解放するように求められるかを決定する要因です。以下で説明するように、これを予測することは難しい場合があります。明確で包括的なメモリメトリクスを提供するために、Hubは単一の数値メトリクスよりも正確な範囲を報告します。
仮想メモリ
現代のオペレーティングシステムは、ユーザープロセスと物理メモリの間に 仮想メモリ と呼ばれる抽象化レイヤーを提供します。プロセスがメモリを要求すると、ほとんどまたはまったくアドレスが物理メモリに即座にマッピングされません。代わりに、OSは内部の記録を行い、いくつかのアドレス範囲が保障されていることを記録し、それらが クリーン であることを示します。
クリーン 状態のメモリは書き込まれていないため、システムがメモリ不足になった場合にその内容を保持する必要はありません。プロセスがメモリに書き込むと、それは ダーティ になり、OSはデータを失うことなくその内容を独自に破棄することはできません。ダーティメモリが一定期間アクセスされない場合、OSはデータをディスクに書き込んで物理メモリを解放する(スワッピング)か、メモリを圧縮して小さくしますが、一時的に使用できなくなります。アプリの メモリフットプリント は、ダーティ、スワップ、および圧縮されたメモリの合計です。
AndroidやLinuxを含むほとんどのUnix系オペレーティングシステムは、仮想メモリが物理ストレージにマッピングできることを保証しません。グローバル使用量が高い場合、需要が利用可能な物理メモリとディスク上のスワップを超えることがあります。その場合、システムはメモリを大量に消費するプロセスを終了させることで安定性を維持しようとします。Windowsは異なるアプローチを取ります。プロセスが仮想メモリを割り当てると、システムはその内容を物理メモリおよび/またはページファイルに保存することを コミット し、グローバル需要がシステム容量を超えないようにします。システムがメモリ不足になることはないため、オーバーコミットされたプロセスを終了させる必要はありません。
ヒープ
OSは現代のデバイス上の非常に大きな仮想アドレス空間を管理する必要があります。仮想アドレスを任意の小さな割り当てにマッピングするために必要なメタデータはカーネルにとって負担となります。したがって、システムには最小割り当てサイズである ページ があり、通常は4〜16 KBの範囲です。もちろん、プログラムは通常、単一ページよりもはるかに小さいオブジェクトを作成します。メモリを効率的に使用するために、malloc は複数のプログラムオブジェクトを1つ以上のOSページにパックするために使用されます。
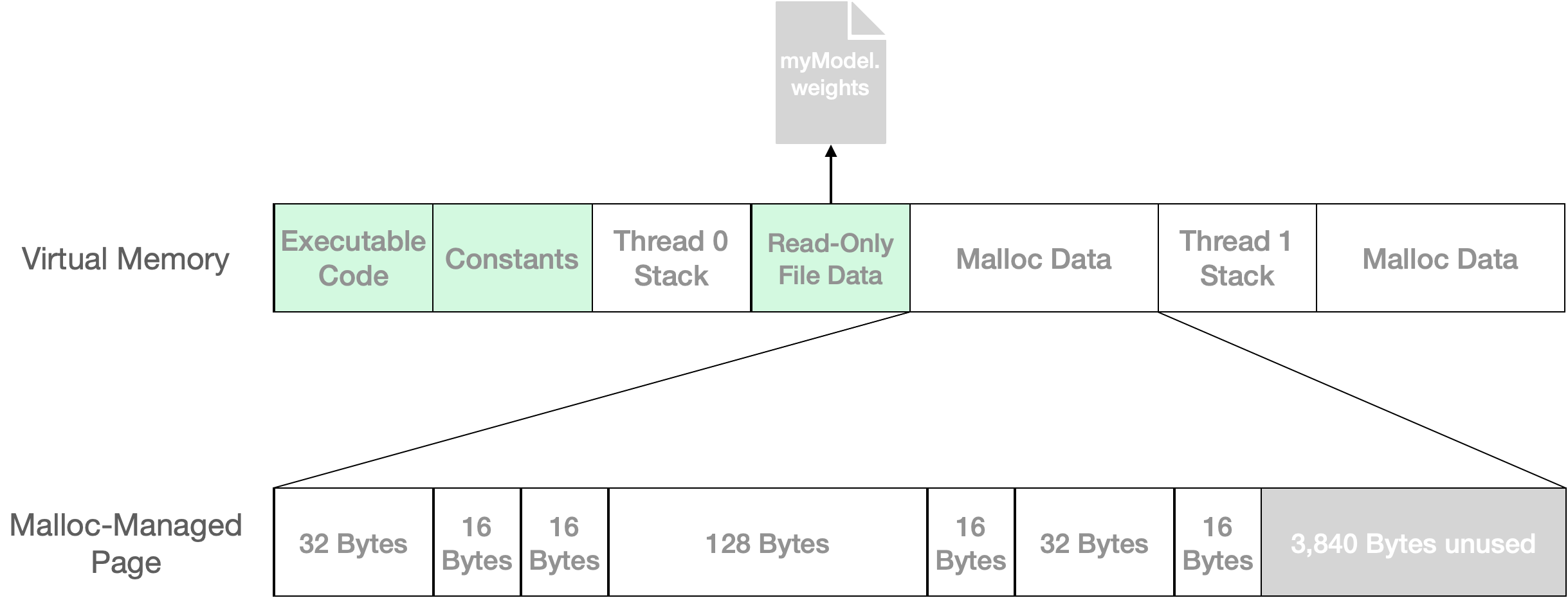
図1: 仮想メモリは、クリーン(緑色で表示)または非クリーンの単位でオペレーティングシステムによって割り当てられます。Mallocは、これらの大きなページに小さなオブジェクトを効率的にパックするためのインターフェースです。この例では、256バイトのユーザーデータが1つの4,096バイトのページにパックされ、3,840バイトが将来のmalloc呼び出しのために利用可能です。
図1は、簡略化された仮想メモリアドレス空間を示しています。クリーン 領域は、OSがユーザーコードを実行せずに再作成できる領域です。これは通常、これらのページが変更されないファイルによってバックアップされているか、単に書き込まれていないためです。一部のオペレーティングシステムの観点から、非クリーンページはアプリケーションのメモリフットプリントを構成します。アプリがダーティ、スワップ、および/または圧縮されたページを過剰に持っている場合、システムがメモリ不足になると終了のリスクがあります。
ほとんどのランタイムデータはmallocによって管理され、そのダーティページは部分的にしか使用されない場合があります。この例では、256バイトのユーザーデータが4 KBのページに保持されていますが、3,840バイトは未使用です。実際のアプリケーションでは、モデルのコンパイルやロードなどのメモリを大量に消費するタスクが、malloc管理ページにかなりの量の未使用スペースを残すことがあります。このメモリは通常、後続のステップで再利用できます。
メモリフットプリントを計算する際、OS提供のツールやAPIはmalloc管理ページの未使用部分の量を認識していません。この未使用メモリの一部またはすべてが再利用される可能性があるため、Androidでは、Hubは最良の場合の完全な再利用と最悪の場合の再利用なしを前提としてメモリ使用量を範囲として報告します
上記のように、Windowsでは状況が異なります。システムが予期せずメモリ不足になることはないため、ユーザープロセスを終了させるメモリモニターはありません。したがって、Windowsでは、Hubのメモリ使用量メトリクスは、既に割り当てられたヒープスペースが後続の要求によって再利用されないことを前提としています。 報告される範囲の両端は、仮想メモリ割り当ての合計であるプロセスコミットチャージです。作業セットサイズを含む追加のメトリクスは、ランタイムログファイルに記載されています。
ピーク対増加
タスクを完了するために使用されるメモリは通常、結果のサイズを超えます。モデルをコンパイルするシナリオを考えてみましょう。コンパイラにメモリリークがないと仮定すると、オンデバイスのモデルをコンパイル済みモデルに変換するために一定量のメモリが必要であり、ディスク上にアーティファクトを残し、メモリ内にはオブジェクトが残りません。コンパイラが40 MBを使用した場合、その ピーク 使用量は40 MBであり、メモリ使用量の定常状態 増加 は0バイトです。
特定のメモリメトリクス
すべてをまとめると、プロファイルジョブは表1に示されるようなメモリメトリクスを返します。この例のCNNモデルのソースは54 MBであり、オンデバイスのコンパイル中に約163 MBが使用されるのは驚くことではありませんが、コンパイル済みモデルがディスクに保存された後はメモリが使用されません。increase の上限は最悪のシナリオを報告し、コンパイル後に残った0.7 MBの未使用malloc管理メモリがアプリによって再利用されないことを前提としています。同様に、モデルのロード後にアプリが保持するデータ量は、最初のロードと次回以降のロードの間で実際には異ならない可能性がありますが、最初のロードでは未使用malloc管理メモリが多く残りました。これは、最初のロードがより多くの作業を行い、したがってより多くの割り当てを行ったためです。
ステージ |
ピーク |
増加 |
|---|---|---|
コンパイル |
162.7 - 163.4 MB |
0.0 - 0.7 MB |
最初のアプリロード |
1.7 - 2.8 MB |
0.6 - 1.7 MB |
次回以降のアプリロード |
1.8 - 2.5 MB |
0.8 - 1.6 MB |
推論 |
629.6 - 630.6 MB |
378.7 - 379.6 MB |
Hubでは、モデルがメモリ圧力に与える最も重要な貢献を強調するピーク範囲を表示し、OSがアプリを終了させる可能性があります。これらおよび他のすべてのメトリクスは、Pythonクライアントライブラリで利用できます。完全なメモリおよびタイミングメトリクスのセットは表2に示されています。
キー |
タイプ |
単位 |
|---|---|---|
|
|
バイト |
|
|
バイト |
|
|
バイト |
|
|
バイト |
|
|
バイト |
|
|
バイト |
|
|
バイト |
|
|
バイト |
|
|
マイクロ秒 |
|
|
マイクロ秒 |
|
|
マイクロ秒 |
|
|
マイクロ秒 |