Frequently Asked Questions
本文件旨在回答 Qualcomm® AI Hub 中常見的問題和工作失敗的原因。請將此作為參考,並隨時在 AI Hub Slack 上提出任何問題。
General
AI Hub上的模型是在實際裝置上運行?
是的,我們通過多個設備農場託管了數千台真實設備。當您使用 AI Hub 並在特定設備上運行模型時,我們會獲取該設備,安裝作業系統和運行模型所需的所有必要框架。然後,我們在該設備上運行您的模型,以獲取 AI Hub 上顯示的所有指標。一旦這個過程完成,我們會釋放該設備。我們對提交到 AI Hub 的每個作業都重複這個過程。要查看我們所有可用的設備,您可以執行 qai-hub list-devices。
AI Hub 的設備配置是如何運作的?許多用戶可以同時在 AI Hub 上的不同設備上運行模型嗎?
是的,我們有許多設備,並且可以在所有這些設備上並行運行模型。當獲取到真實設備時,該設備上只會運行您的特定模型。
是的,當用戶提交任務時,會為每個任務分配單獨的設備,以提供準確的指標。
如何設置我的 API token以在 AI Hub 上提交任務?
一旦您創建了 Qualcomm MyAccount,請登錄 Qualcomm® AI Hub,並訪問設置頁面以獲取您的唯一 API Token。我們建議觀看 有關此主題的操作視頻以獲取詳細說明。
如何將我的團隊或其他團隊的成員添加到 AI Hub 以查看我的作業?
- AI Hub 作業可以自動與您的組織共享。如果您想添加的話
如果您的團隊中有開發人員擁有 AI Hub 帳戶,請將其添加到您的組織中。請將電子郵件地址發送至 ai-hub-support@qti.qualcomm.com。
AI Hub 作業也可以與您的組織外部和 Qualcomm 共享以獲取支持。點擊任何作業右上角的“共享”按鈕,並指定 AI Hub 用戶的電子郵件,該作業(及其相關的模型資產)將被共享。您還可以通過從作業中刪除電子郵件地址來撤銷訪問權限。
哪裡可以找到已經過AI Hub優化的模型?
您可以前往以下任意位置找到已經在 AI Hub 上預先優化的模型。我們目前有超過 150 個優化模型,並且不斷添加新的模型:
Qualcomm® AI Hub Models, Qualcomm's Hugging Face, Qualcomm® AI Hub Models
我可以在AI Hub上執行自己的模型?
是的,這個功能對任何人都可用!請注意,某些模型可能會失敗,這是由於以下原因:
這個模型檔案很大(i.e. > 2GB).
模型在 PyTorch 中可能會失敗,請按照錯誤消息進行相應的模型更改:
如果模型有分支(if/else),在
torch.jit.trace過程中設置check_trace=False可以解決這個問題。
LLMs/GenAI 模型可能不適用:
這些大型模型通常需要量化才能在設備上有效運行。請參考我們的 LLM 配方以獲取指導。
Misc. conversion issues:
轉換可能會在內部失敗,如果您遇到不明確的錯誤消息(例如內部設備錯誤),請告訴我們,我們將盡力及時調查問題。對更多模型的支持正在不斷增加!
如果編譯作業失敗,請確保提供的輸入規格與模型兼容。
要在 AI Hub 上提交您的第一個作業,我們建議觀看 有關此主題的操作視頻。如果您遇到任何問題,請通過 AI Hub Slack 與我們聯繫!
我可以使用 HuggingFace 上的模型,而不是 Qualcomm AI Hub 模型嗎?
是的!這些都是很好的模型可以嘗試。如果您有一個適合您使用情況的模型,但我們沒有列出,請查看 https://huggingface.co/models 並選擇一個模型。然後,您可以匯入必要的函式庫並在提交編譯作業之前跟踪模型。(請參閱下面提交作業時常見的錯誤。)
我可以在實際的裝置上執行經AI Hub量化的模型?
是的。我們在 Qualcomm® AI Hub Models 中列出了一些量化模型,您可以在模型精度部分進行篩選以查看它們的性能。這些模型是使用 AIMET 進行量化的,但它們正在過渡到使用 量化。
如果您想要使用自己的量化模型,我們建議使用 量化,因為它會將未量化的 ONNX 模型作為輸入並生成量化的輸出。
如何在 Qualcomm® AI Hub 上的特定設備上運行我的模型?
當您提交模型時,您需要指定目標設備。若要獲取可用設備的列表,請運行 qai-hub list-devices。從可用設備列表,您可以透過設備的名稱或任何屬性來指定目標設備。例如,device = hub.Device(attributes="qualcomm-snapdragon-845") 將在任何具有 845 芯片的設備上運行,而 device=hub.Device("QCS6490 (Proxy)") 則會專門在 6490 代理設備上運行。我們還有設備系列,您會在列表中看到適用的設備旁邊顯示,例如 Google Pixel 3a 系列、Samsung Galaxy S21 系列等。這有助於設備配置時間,減少特定名稱設備的排隊時間。它將始終提供您指定芯片組的設備。請在適當時候使用此選項!我們建議觀看 有關此主題的操作視頻。
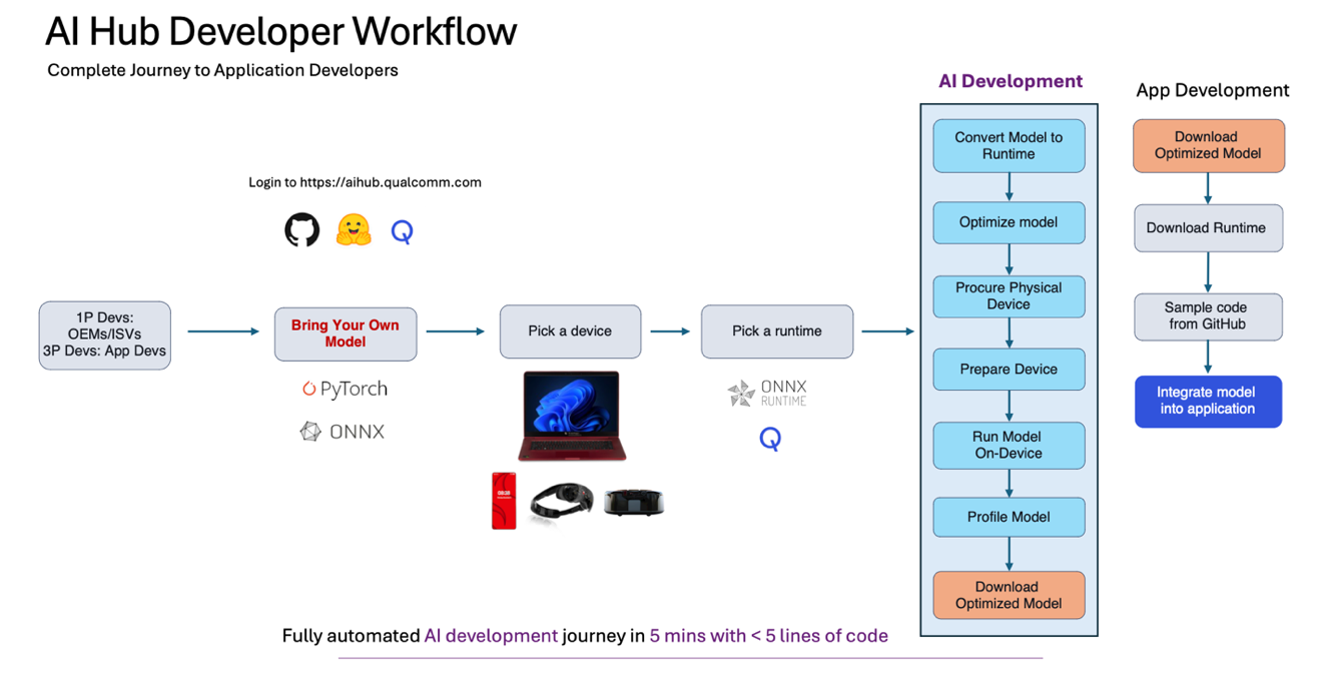
一般使用AI Hub的工作流程為何?
步驟 1:為您的使用案例選擇模型,可以從 Qualcomm® AI Hub Models 中選擇,或者使用您自己的模型。
步驟 2:提交編譯任務,以便將您訓練的模型(PyTorch、ONNX、AIMET 量化模型)編譯到指定的設備上(使用 qai-hub list-devices 來確定可用的設備)以及 desired target runtime.
步驟 3:提交分析任務,在雲端託管的真實設備上運行您編譯的模型並分析其性能(例如,它是否達到您的延遲目標、內存限制,是否在所需的計算單元上運行)。在這裡,您將獲得大量關於模型性能的豐富指標,例如每層的計時、每層的可視化、加載和推理時間以及運行時日誌信息,這些信息在您的任務失敗時可能至關重要。
步驟 4:提交推理任務,上傳輸入數據,在真實設備上運行推理並下載輸出結果。
步驟 5:對設備上的輸出結果進行任何必要的後處理計算,以確認模型的準確性。
步驟 6:以編程方式下載優化後的模型,並將其整合到您的應用程序中。查看我們的 示例應用 程序以獲取將模型整合到應用程序的幫助。
為什麼我的模型在推理任務中的延遲與分析任務中的延遲不同?
當您提交一個分析任務時,將會在指定的設備上執行100次推理。這是為了提供一個準確的指標,告訴您將其打包到應用程序中時預期需要多長時間。由於啟動時間、緩存預熱等原因,第一次迭代通常是最慢的。配置任務中推理執行的次數可以通過選項 max_profiler_iterations 來調整。然而,推理任務只在指定的設備上運行一次,因為其核心目的是進行準確性計算,以確認模型在數值上是等效的並準備好下載和部署。
我已經使用 AI Hub 運行了我的模型並下載了優化後的模型,接下來該怎麼做?
好問題!下一步是將模型資產打包到您的應用程序中,以便在目標設備(移動設備、物聯網、個人電腦等)上部署。我們有一些 示例應用程序 來展示如何進行這一步,並且我們正在努力提供更多相關資源。具體來說,當使用 Qualcomm® AI Engine Direct 整合 .bin 文件時,請查看 這些文檔。我們正在積極增加更多示例應用程序和相關信息。對於將應用部署到 Rb3Gen2 的物聯網客戶,我們建議利用 Foundries.io 與從 AI Hub 優化的模型結合使用.
AI Hub 上發布的模型的許可條款是什麼?我可以在我的應用程序中使用這些模型並將其發布給用戶嗎?
AI Hub 模型展示了一系列預先優化的開源模型。每個模型的許可證可以在相應的模型頁面上找到。
自帶的模型其許可條款會是什麼?這會成為 Qualcomm 的IP嗎?
AI Hub 是一個為設備優化模型的平台。如果您“自帶模型”,那麼從 AI Hub 獲得的部署資產通常具有與您的模型相同的發佈許可。如果這是您自己的知識產權,那麼該模型由您自行發佈。更多詳細信息可以在我們的服務條款中找到。
使用 AI Hub 或 AI Hub 模型在我的生產應用程序中,或將其集成到 AI Hub 進行模型測試時,是否會產生任何費用?
AI Hub,我們的平台,目前完全免費使用。我們鼓勵您提交您的模型,編譯它們,分析並迭代性能,提交推理任務以檢查準確性,並下載目標資產以打包到您的應用程序中。
在我們的模型集合中,有一些特定的模型是由模型製作者提供的,根據其許可證需要購買。請聯繫我們以獲取更多信息。如果某個模型在 aihub.qualcomm.com 上標示為 'download now',則該模型是免費且開放使用的。請查看模型頁面上列出的許可證,並根據許可使用該模型。
如果 AI Hub 在雲端運行模型,這樣做是否安全?其他用戶能看到我上傳的模型嗎?
除非您明確與其他使用者分享,否則您在 AI Hub 上的所有操作都是私密且安全的。這包括所有上傳的資料集與模型,以及透過 AI Hub 工作建立的模型、資料集或指標。客戶的資料在工作完成後會從實體裝置的暫存儲存空間及其他雲端運算環境中清除。其他使用者無法查看您的私人資訊。
請參閱 Qualcomm privacy policy 以了解 Qualcomm 如何收集與使用資料。如有任何疑問,請透過電子郵件聯絡我們: email us。
如何為我的組織增加新成員?
每個用戶都有自己的組織,用戶的模型和數據會安全地保存在他們的組織中,只有他們和他們添加到組織中的人才能訪問。如果您希望在 AI Hub 中添加任何人到您的組織,請告訴我們,這樣他們就可以看到您的工作,您也可以看到他們的工作。
如果您希望將某人添加到特定的工作中,我們建議使用任何工作右上角的分享按鈕,並添加他們的電子郵件地址
如何得知AI Hub的更新?
我們會在 AI Hub Slack 上即時發布我們的版本說明!您也可以在 我們的文檔 中找到它們.
Model Formats
為何 Qualcomm® AI Hub Models 僅提供一些 TensorFlow Lite 模型的效能資訊?
如果您訪問我們超過100個預優化模型的集合,根據模型的不同,您可能只會看到 TensorFlow Lite 或 Qualcomm® AI Engine Direct 的結果。我們正在努力提供這兩種方面的性能結果,屆時您將在下拉選單中看到 TorchScript → TensorFlow Lite 和 TorchScript → Qualcomm® AI Engine Direct,您可以選擇想查看的性能數據。此外,如果您訪問我們的 Compute Models,在適用的情況下,您還會看到 TorchScript → ONNX Runtime 的性能結果。
如何挑選模型運行環境? TensorFlow Lite, ONNX Runtime or Qualcomm® AI Engine Direct?
有些已知問題會導致某些路徑比其他路徑更快,這取決於模型。我們的持續目標是跟蹤並解決這些問題,無論在哪條路徑上。隨著我們對大多數模型進行優化,您可以預期它們的性能會大致相同。最終,所有路徑都會通向相同的 QNN 和相同的硬件,因此沒有任何根本性的區別。TensorFlow Lite 將通過 TensorFlow Lite Delegate 訪問 Hexagon NPU,ONNX Runtime 將通過 ONNX 執行提供程序訪問 Hexagon NPU,而 Qualcomm® AI Engine Direct 當然會利用 Hexagon NPU。
我們建議 Android 開發者在部署到移動設備時使用 TensorFlow Lite,Windows 開發者和那些部署到筆記型電腦的開發者使用 ONNX Runtime,而 Qualcomm® AI Engine Direct 則取決於 SOC / 作業系統。我們強烈建議嘗試不同的runtime,並使用為您的目標設備提供最佳性能的路徑。
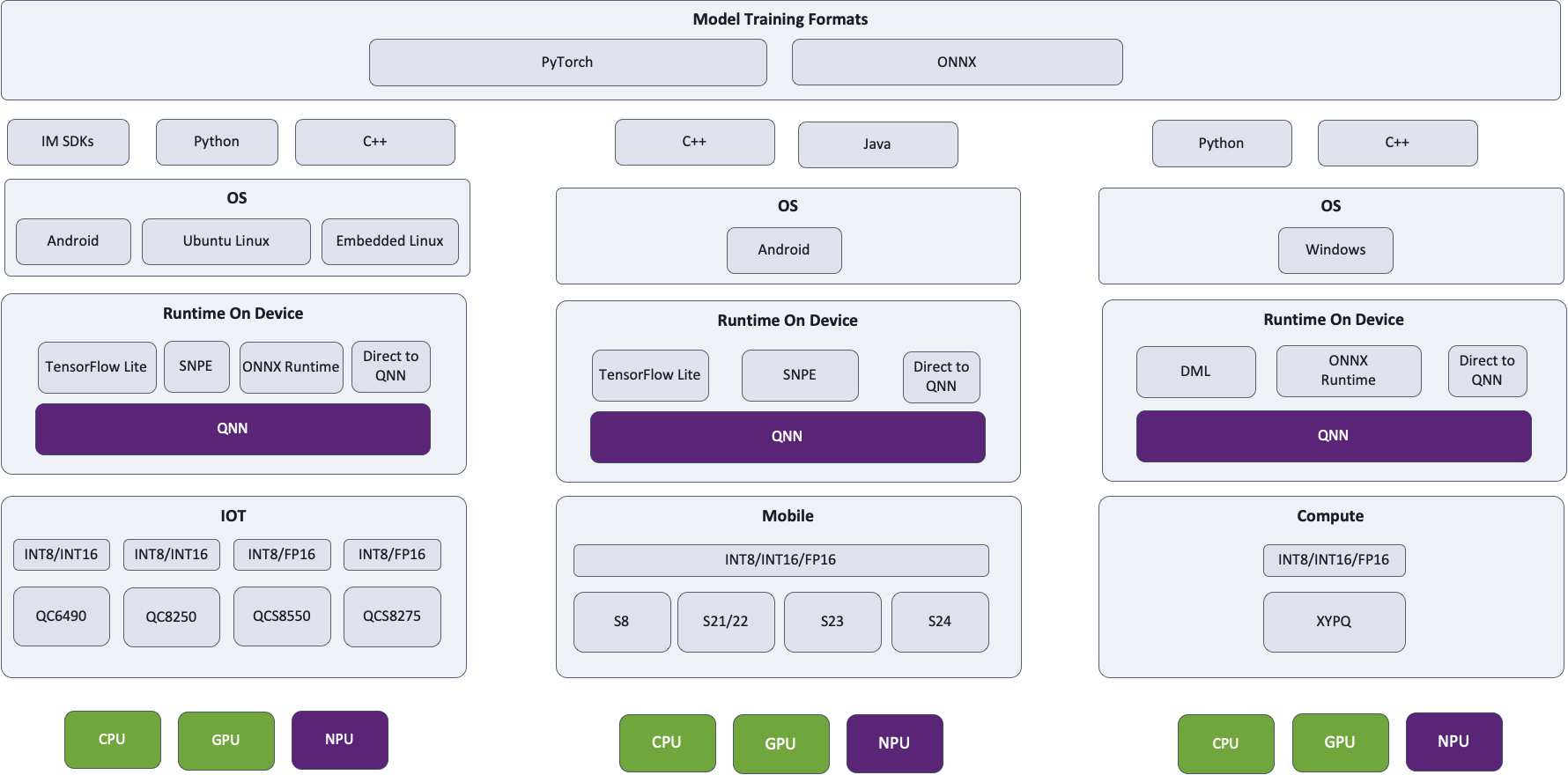
這是我們的架構圖,無論選擇哪條路徑和指定哪個運行時,都會使用 QNN 並在適用的情況下利用 Hexagon NPU。Hub 將始終在最優的計算單元上運行模型。
我應該使用哪種 Qualcomm® AI Engine Direct 模型格式?
Qualcomm® AI Engine Direct SDK 支持三種格式的設備上執行:模型庫(.so 和 .dll)、上下文二進制文件(.bin)和深度學習容器(.dlc)。這些格式之間存在重要差異,可能會影響運行時性能。
模型庫(
--target_runtime qnn_lib_aarch64_android)是導出單個函數的動態庫。調用它將使用 QNN 圖構建函數來實例化您的模型。雖然這種格式是特定於操作系統的,但最終的圖將針對運行它的設備進行優化,以確保最佳的推理性能。深度學習容器(DLC)類似於模型庫,因為它們包含網絡的 SoC 無關表示。它們還可以嵌入針對特定目標 SoC 集的上下文二進制文件,儘管這尚未普遍使用。通常,這種 OS 無關格式用於在進一步的設備特定優化之前驅動 QNN 級別的圖數據結構構建。
上下文二進制文件是與作業系統無關的、專用於 HTP 的格式。它們相當於加載模型庫,為特定的 SoC 準備圖形(即允許 QNN 為特定的 HTP 調用 Hexagon 編譯器),並保存生成的數據結構。由於 Hexagon 編譯器對所使用的 HTP 做出假設,因此上下文二進制文件僅在針對特定 HTP 時才能實現最佳性能;通常可以在較新的芯片上使用為較舊設備構建的二進制文件,但性能可能會受到影響。
為了實現最佳性能,請確保為
qnn-context-binary-generator指定正確的soc_model。您可以通過查閱 Qualcomm® AI Engine Direct 的支持 Snapdragon 設備表來找到正確的值,該表在 Overview 中提供,也可以在 SDK 的docs/QNN/index.html中找到,然後點擊Overview。此外,它還會顯示在每個針對 Qualcomm® SoC 設備的 Qualcomm® AI Hub 運行時日誌的頂部附近。
Qualcomm® AI Engine Direct Model Format Summary
Format |
Backends |
OS Agnostic |
SoC Agnostic |
Time to Load |
Inference Performance |
|---|---|---|---|---|---|
Library |
Any |
No |
Yes |
Longer |
Optimal |
DLC |
Any |
Yes |
Yes |
Longer [1] |
Optimal |
Context Binary |
HTP |
Yes |
No |
Fastest |
Optimal [2] |
我可以將模型資產從代理設備部署到實際硬體上嗎?
TL;DR -- TensorFlow Lite 和 ONNX Runtime 資產應該沒問題,但 QNN 模型格式可能會有問題。
過去,代理設備被添加到 AI Hub 中,以便為具有類似性能特徵但不受 AI Hub 支持的流行設備提供分析和推理。例如,RB3 Gen 2 中的 QCS6490 與幾款移動設備中的 SM7325 本質上是相同的芯片。雖然這對於基準測試和準確性評估非常有用,但在生成 QNN 模型格式時可能會出現挑戰:
模型庫是作業系統專屬的。代理設備通常運行 Android,但實際設備可能使用 Linux。
上下文二進制文件是 SoC 特定的。雖然我們預期針對代理設備會在真實設備上提供良好的性能,但這並不是一個保證。
在某些情況下,會使用完全不同版本的 QNN SDK。例如,所有車用代理設備都是移動設備,但所有 Cockpit、ADAS 和 Flex 設備都需要使用特定的車用 SDK,該 SDK 了解同一代車用和移動芯片之間的差異(例如,SA8295P 的 V68 HTP 上的 fp16 支持)。
幸運的是,第三方框架通過在加載時進行優化,避免了所有這些問題,使得 TensorFlow Lite 和 ONNX Runtime 資產在這種情況下成為不錯的部署選擇。
Passing Options
如何指定運算處理器?
當在 AI Hub 上提交任何類型的工作時,請使用選項 --compute_unit 來指定您希望模型運行的計算單元。如果您希望指定多個計算單元,請用逗號分隔,例如 --compute_unit npu,cpu。我們建議觀看 how-to video on this topic。
如何指定目標runtime?
Qualcomm® AI Hub 支援 TensorFlow Lite、ONNX Runtime 和 Qualcomm® AI Engine Direct (上下文二進制和模型庫)作為目標runtime。在提交編譯工作時,請使用 --target_runtime <runtime> 選項來指定runtime。我們建議查看 how-to video on this topic。
如何確定NPU正在被使用?
每個目標runtime都有其自己的策略來充分利用可用的硬體。在性能和能力之間存在權衡:NPU 通常提供最佳性能,但在計算能力上最受限。相反,CPU 雖然不適合神經網絡推理,但可以執行任何操作。支援多個硬體後端的runtime通常會盡可能多地在 NPU 上運行網絡,然後再回退到 GPU 或 CPU。
要啟用 NPU 使用,運行時必須 (1) 配置為使用 NPU,並且 (2) 網絡應避免使用不支援的操作或參數。
預設情況下,AI Hub 支援runtime切換,以便在降級到 GPU 和/或 CPU 之前使用 NPU。要強制使用 NPU,請指定編譯/運行時選項 --compute_unit npu。還可以考慮使用 QNN 目標runtime,例如 qnn_lib_aarch64_android。
導致層無法部署至 NPU 的常見原因包括不支援的運算節點(op),或不支援的張量維度(rank),特別是在 rank ≥ 5 的情況下,支援度會相對較低。當這種情況發生在支援異質運算調度的執行環境(例如 TensorFlow Lite)時,這些層應會自動回退至 GPU 或 CPU 執行。在某些情況下,整個網路可能會從 NPU 上離開,這通常是因為在裝置端準備網路時發生了較為非預期的錯誤。此時,網路將會在 GPU 或 CPU 上執行。若發生此情況,請透過 AI Hub Slack 聯繫我們,我們將樂意協助檢視該任務。
如何指定優化選項?
預設情況下,AI Hub 會始終優化模型以提高runtime性能。有時,這可能會成為問題,因為所需的時間過長:一些大型模型可能會導致工作超時,因為 Hexagon 編譯器的工作量過大。很少情況下,更高的優化級別會產生更差的代碼。在這種情況下,降低優化級別可能是合理的。如何降低優化級別取決於目標runtime環境。
針對NPU的 Qualcomm® AI Engine Direct (例如,
--target_runtime=qnn_lib_aarch64_android --compute_unit all),請使用--qnn_options=default_graph_htp_optimization_value=x,其中x可以是1或2。請注意,當使用qnn_lib_*時,Hexagon 編譯是 在設備上 進行的,但在針對qnn_context_binary時,則是在模型轉換期間提前進行的。針對將 TensorFlow Lite 委派給 Qualcomm® AI Engine Direct (即
--target_runtime=tflite)並成功委派到NPU的情況,請使用--tflite_options=kHtpOptimizeForPrepare,這會將 QNN 優化級別設置為1。當針對tflite時,Hexagon 編譯始終在設備上進行。
常見的作業失敗以及已知的問題
我的編譯工作失敗,並顯示一個操作缺失的錯誤訊息。我該怎麼辦?
如果您收到類似 Failure occurred in the ONNX to Tensorflow conversion: Op 'xx' is not yet implemented 的錯誤,請隨時在 AI Hub Slack 上聯繫我們。我們可能會優先考慮添加操作支持(或者這項工作已經在進行中)。如果沒有,我們可以在適用的情況下提供解決方法。
即使我在文檔中傳遞了一個選項,我的任務仍然失敗了,我該怎麼辦?
確保您正在為正確的工作類型傳遞選項(例如,編譯與分析)。例如,--quantize_full_type 是一個編譯工作選項;將其傳遞給分析工作將導致失敗。如果您仍然遇到問題,請在 AI Hub Slack 上聯繫我們。
我的 Hugging Face 模型因為不支持 "DictConstruct" 而失敗。我該怎麼辦?
我們建議將 model.config.return_dict = False。預設值是 true。目前,Hub 無法自動處理字典作為輸出。我們已將此問題列入待辦事項。暫時的解決方法是編寫一個包裝模塊,將字典轉換為元組。
我的分析任務失敗,顯示錯誤訊息為 "request feature arch with value [0-9]+ unsupported",這是什麼意思?
當上下文二進位檔為比目標設備支持的更新版本的 Hexagon 架構時,會出現此錯誤。要解決此問題,請使用將用於剖析或推理的設備重新編譯源模型。
我的分析作業失敗了, 並引用錯誤代碼 3110。為什麼會發生這種情況?
此錯誤表示無法為設備準備模型。可能發生這種情況的原因有幾個:
浮點數不支持。失敗的節點型態,錯誤代碼3110。當節點的輸入或輸出類型不被QNN後端支持時,會發生3110錯誤。這通常是由於節點未正確量化或未量化的張量,從而導致錯誤。要解決此問題,請量化(或重新量化)模型。操作符定義和約束可以在 HTP Backend Op Definition Supplement。
不支持的維度。許多操作僅支持小於5維的數據。一些操作支持5維,但沒有操作支持大於5維的數據。
不支持的類型。許多操作不支持所有類型。這個錯誤在 [u]int32 層中相當常見。
我的分析作業失敗,錯誤代碼為 1002,位置在 qnn_model.cc:167 onnxruntime::qnn::QnnModel::FinalizeGraphs,我該怎麼做?
如果執行時日誌未提供有用資訊,我們建議使用以下選項重新進行分析:--runtime_debug=true --max_profiler_iterations=1。使用這些設定後,執行時日誌通常會提供更多有關問題原因的資訊。
Deployment
為什麼我的模型在我的設備上運行得比在 Hub 上慢?
在 Hub 中,我們嘗試創建一個現實的環境,以盡可能快地運行模型。我們假設開發人員最常將模型部署到具有用戶界面的應用程序中,因此我們的分析器就是這樣實現的。預設情況下,我們在最高可用功率設置下運行它,以實現最快的推理速度。讓我們來看看這些選擇的結果。
Scheduling Priority
Hub 的分析器是一個在所有支持的移動和車用設備上運行的 Android 應用程序。這意味著它在內核級別享有優先排程。Android 預設這樣做是為了提供迅速回應的用戶界面。然而,這種策略並不適用於通過 adb shell 運行的 CLI 工具,包括 qnn-net-run。這導致了 GUI 和 CLI 工具之間的性能差距。這種影響可能相當顯著。在對 65 種不同的 Android 設備上運行 MobileNetV2 的試驗中,我們發現使用 CLI 版本的分析器相比於生產中使用的 GUI 版本,平均 [3] 慢了 9.7%。要以與 GUI 應用相同的調度優先級運行 CLI 工具,可以使用具有 root 權限的 nice -n -10 YOUR_TOOL。
Power Settings
預設情況下,Hub 會在所有移動設備上請求 BURST 電源設置。這通常會比預設設置顯著加快執行速度。在您的應用程序中啟用此功能的步驟取決於所使用的機器學習框架。ONNX Runtime 和 TensorFlow Lite 有設置可以代您設置這些選項。而對於 Qualcomm® AI Engine Direct,則需要按照上述鏈接頁面中的說明,單獨設置電壓和其他選項。
Profile Settings
收集詳細的分析數據(例如,qnn-net-run --profiling_level detailed)可能會引入大量的開銷。建議僅在需要比較網絡層的相對運行時間時使用。
Other Settings
AI Hub 覆蓋框架預設設置(包括您指定的設置)的選項可以在推理和分析任務頁面的 "Runtime Configuration" 設定中找到。特別需要注意的是,fp16_relaxed_precision 預設是啟用的。
為何在使用HTP時出現錯誤代碼 1008 ?
錯誤 1008,也稱為 QNN_COMMON_ERROR_INCOMPATIBLE_BINARIES,通常表示初始化 HTP 失敗。這通常是因為找不到包含在 HTP 上運行的程式庫 [4]。在大多數平台上,環境變數 ADSP_LIBRARY_PATH 必須設置為包含與設備的 DSP 架構對應的 skel 文件的目錄 [5]。更多信息可以在 QNN 教程 中找到。
這個方法沒有用; 我是使用Windows作業系統
另外有兩件事可檢查.
首先,骨架文件應該放在與 QnnHtp.dll 相同的目錄中。我們曾見過文件建議 ADSP_LIBRARY_PATH 在其他平台上有效,但我們的經驗是它在 Windows 上被忽略了。
其次,Windows 還要求與骨架文件一起發佈的 .cat 文件可用:在將骨架庫複製到應用程序的可執行目錄時,不要忘記 .cat 文件。
如何使用車用設備上的HTP?
在車用客戶端虛擬機中使用 HTP 需要額外的步驟,除了如上所述設置 ADSP_LIBRARY_PATH 之外:還需要將兩個文件從 QNX 主機複製到客戶端虛擬機中。具體來說,這些文件必須複製到 ADSP_LIBRARY_PATH 中的一個目錄中,通常是包含適當骨架庫的目錄。
具有 /dspfw 和 /dsplib 分區的裝置:
/dsplib/image/dsp/cdsp0/libc++.so.1/dsplib/image/dsp/cdsp0/libc++abi.so.1
不具備 /dspfw 和 /dsplib 分區的裝置:
/mnt/etc/images/cdsp0/libc++.so.1/mnt/etc/images/cdsp0/libc++abi.so.1
如果您有其他問題未在此涵蓋,請在 AI Hub Slack 上聯繫我們。