자주 묻는 질문
이 문서는 Qualcomm® AI Hub 에서 자주 묻는 질문과 작업 실패의 이유를 설명하기 위한 것입니다. 참고 자료로 사용하시고, AI Hub Slack 에서 질문이 있으면 언제든지 문의하세요.
일반
모델이 실제 장치에서 실행되나요?
네, 우리는 여러 장치 팜에 수천 대의 실제 장치를 호스팅하고 있습니다. AI Hub를 사용하여 특정 장치에서 모델을 실행하면, 해당 장치를 가져와 OS와 모델 실행에 필요한 모든 프레임워크를 설치합니다. 그런 다음 해당 장치에서 모델을 실행하여 AI Hub에 표시된 모든 메트릭을 캡처합니다. 이 과정이 완료되면 장치를 반환합니다. AI Hub에 제출된 모든 작업에 대해 이 과정을 반복합니다. 우리가 갖고 잇는 장치 종류를 보려면 qai-hub list-devices 를 실행해 주세요.
AI Hub에서 장치 프로비저닝은 어떻게 작동하나요? 여러 사용자가 AI Hub에서 동시에 다른 장치에서 모델을 실행할 수 있나요?
네. 우리는 많은 장치를 보유하고 있으며, 모든 장치에서 모델을 병렬로 실행할 수 있습니다. 실제 장치가 조달되면 해당 장치에는 귀하의 특정 모델만 실행됩니다.
네, 사용자가 작업을 제출하면 각 작업에 대해 별도의 장치가 조달되어 정확한 메트릭을 제공합니다.
AI Hub에서 작업을 제출하려면 API 토큰을 어떻게 설정하나요?
Qualcomm MyAccount를 생성한 후 Qualcomm® AI Hub 에 로그인하고 설정 페이지로 이동하여 고유한 API 토큰을 가져오세요. 자세한 지침은 이 주제에 대한 동영상 가이드 를 시청하는 것을 권장합니다.
AI Hub에서 내 작업을 다른 사람과 공유하려면 어떻게 하나요?
- AI허브 작업은 조직 위부와 자동으로 공유할 수 있습니다.
조직에 사용자를 추가하려면 팀원의 이메일 주소를 포함하여 ai-hub-support@qti.qualcomm.com 로 이메일을 보내주세요.
AI Hub 작업은 지원을 받기 위해 조직 외부 및 Qualcomm과도 공유할 수 있습니다. 작업의 오른쪽 상단에 있는 “공유” 버튼을 클릭하고 AI Hub 사용자의 이메일을 지정하면 작업(및 관련 모델 자산)이 공유됩니다. 이메일 주소를 작업에서 제거하여 액세스를 취소할 수도 있습니다.
AI Hub에서 이미 최적화된 모델을 어디에서 찾을 수 있나요?
AI Hub에서 사전 최적화된 모델을 찾을 수 있는 위치는 다음과 같습니다. 현재 150개 이상의 최적화된 모델이 있으며, 계속해서 새로운 모델을 추가하고 있습니다:
Qualcomm® AI Hub Models, Qualcomm’s Hugging Face, Qualcomm® AI Hub Models
내 모델을 가져와 AI Hub에서 실행할 수 있나요?
네. 이 기능은 누구나 사용할 수 있습니다! 성공할 모델에 대한 알려진 제한 사항이 있음을 유의하세요. 모델이 컴파일에 실패할 수 있는 이유는 다음과 같습니다:
모델이 큽니다 (즉, > 2GB).
모델이 PyTorch에서 추적에 실패할 수 있습니다. 오류 메시지를 따라 모델을 변경하세요:
모델에 분기(if/else)가 있는 경우,
torch.jit.trace중check_trace=False로 설정하면 문제가 해결됩니다.
LLM/GenAI 모델은 처음부터 실패할 수 있습니다:
이러한 대형 모델은 장치에서 효과적으로 실행되기 위해 양자화가 필요합니다. LLM 레시피를 참조하세요.
기타 변환 문제:
내부적으로 변환이 실패할 수 있습니다. 명확하지 않은 오류 메시지가 발생하면 알려주세요 (즉, 내부 장치 오류). 문제를 신속하게 조사하기 위해 최선을 다하겠습니다. 더 많은 모델에 대한 지원이 계속 증가하고 있습니다!
컴파일 작업이 실패하면 제공된 입력 사양이 모델과 호환되는지 확인하세요.
AI Hub에서 첫 번째 작업을 제출하려면 이 주제에 대한 동영상 가이드 를 시청하는 것을 권장합니다. 문제가 발생하면 AI Hub Slack 에 문의하세요!
Qualcomm AI Hub Models에 없는 HuggingFace 모델을 시도할 수 있나요?
네! 이러한 모델은 시도해 볼 만한 가치가 있습니다. 사용 사례에 적합한 모델이 목록에 없으면 https://huggingface.co/models 를 확인하고 모델을 선택하세요. 필요한 패키지를 가져오고 컴파일 작업을 제출하기 전에 모델을 추적할 수 있습니다. (작업 제출 시 발생하는 일반적인 오류는 아래를 참조하세요.)
AI Hub에서 실제 장치로 양자화된 모델을 실행할 수 있나요?
네. Qualcomm® AI Hub Models 에 나열된 일부 양자화된 모델이 있으며, 모델 정밀도 섹션에서 필터링하여 성능을 확인할 수 있습니다. 이러한 모델은 AIMET 로 양자화되었지만, 양자화 (Quantization) 을 사용하도록 전환 중입니다.
자신의 양자화된 모델을 가져오고 싶다면, 양자화 (Quantization) 을 사용하여 양자화되지 않은 ONNX를 가져와 출력으로 양자화하는 것을 권장합니다.
Qualcomm® AI Hub에서 특정 장치에서 모델을 실행하려면 어떻게 하나요?
모델을 제출할 때 대상 장치를 지정해야 합니다. 사용 가능한 장치 목록을 얻으려면 qai-hub list-devices 를 실행하세요. 거기에서 이름이나 속성으로 장치를 지정할 수 있습니다. 예를 들어, device = hub.Device(attributes="qualcomm-snapdragon-845") 는 845 칩이 있는 모든 장치에서 실행되며, device=hub.Device("QCS6490 (Proxy)") 는 6490 프록시 장치에서 실행됩니다. 또한 장치 목록 옆에 표시되는 장치 패밀리가 있으며, 이는 특정 이름을 가진 장치에 대한 대기 시간을 줄이는 데 도움이 됩니다. 지정한 칩셋을 가진 장치를 항상 제공합니다. 이 옵션을 사용할 수 있을 때 사용하세요! 이 주제에 대한 동영상 가이드 를 시청하는 것을 권장합니다.
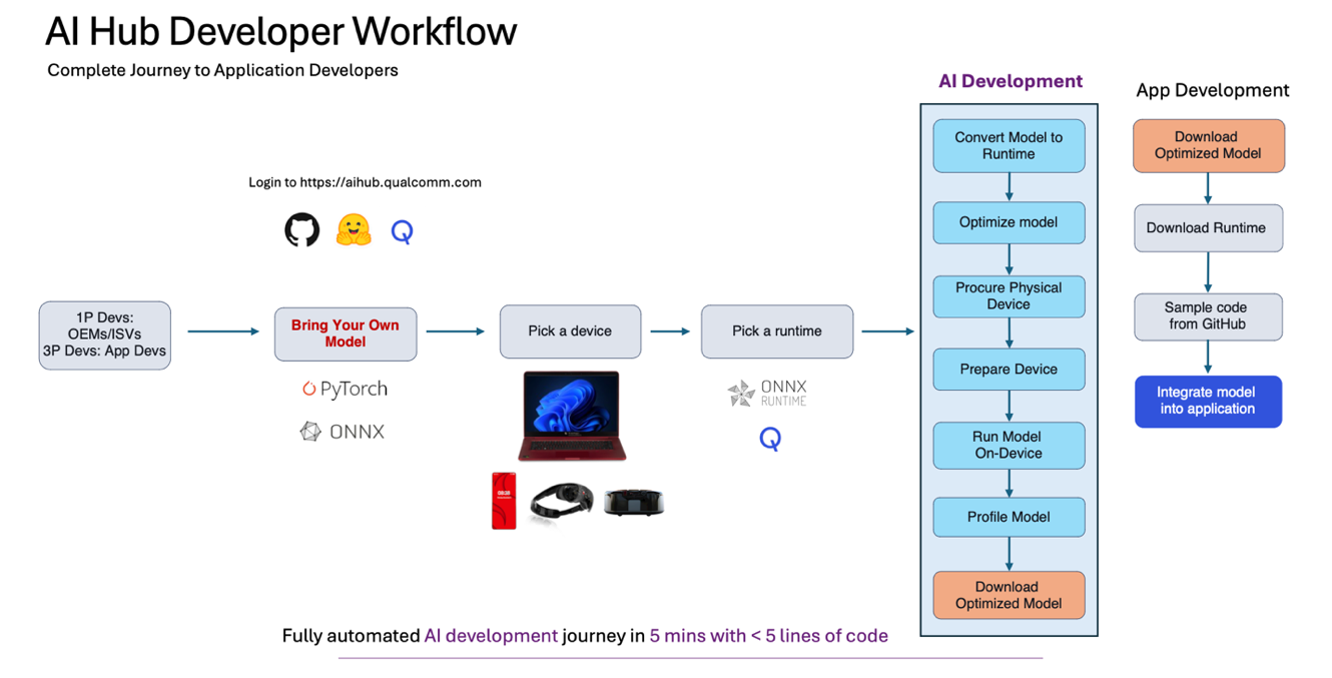
AI Hub를 사용하는 일반적인 개발자 흐름은 무엇인가요?
1단계: Qualcomm® AI Hub Models 에서 사용 사례에 맞는 모델을 선택하거나 자신의 모델을 가져옵니다.
2단계: 컴파일 작업을 제출하여 훈련된 모델 (PyTorch, ONNX, AIMET 양자화 모델)을 지정된 장치에 대해 컴파일합니다 (사용 가능한 장치를 확인하려면 qai-hub list-devices를 사용) 및 원하는 대상 런타임.
3단계: 프로파일 작업을 제출하여 클라우드에 호스팅된 실제 장치에서 컴파일된 모델을 실행하고 성능을 분석합니다 (즉, 지연 시간 목표, 메모리 제한을 충족하는지, 원하는 컴퓨팅 유닛에서 실행되는지). 여기서 모델의 성능에 대한 풍부한 메트릭을 얻을 수 있습니다. 예를 들어, 레이어별 타이밍, 각 레이어의 시각화, 로딩 및 추론 시간, 작업 실패 시 중요한 런타임 로그 정보 등을 확인할 수 있습니다.
4단계: 추론 작업을 제출하여 입력 데이터를 업로드하고, 실제 장치에서 추론을 실행하고, 출력 결과를 다운로드합니다.
5단계: 장치 출력에 필요한 후처리 계산을 수행하여 모델의 정확성을 확인합니다.
6단계: 최적화된 모델을 프로그래밍 방식으로 다운로드하여 애플리케이션에 통합합니다. 모델을 애플리케이션에 통합하는 데 도움이 되는 샘플 앱 을 확인하세요.
왜 내 모델의 추론 작업 지연 시간이 프로파일 작업과 다른가요?
프로파일 작업을 제출하면 지정된 장치에서 추론이 100번 발생합니다. 이는 애플리케이션에 번들로 묶을 때 예상되는 시간을 정확하게 나타내기 위함입니다. 첫 번째 반복은 시작 시간, 캐시 워밍업 등으로 인해 종종 가장 느립니다. 프로파일 작업 중 수행되는 추론 횟수는 max_profiler_iterations 옵션으로 사용자 정의할 수 있습니다. 그러나 추론 작업은 지정된 장치에서 한 번만 실행되며, 주요 목적은 정확도 계산을 수행하여 모델이 수치적으로 동일하고 다운로드하여 배포할 준비가 되었는지 확인하는 것입니다.
AI Hub를 사용하여 모델을 실행하고 최적화된 모델을 다운로드했습니다. 이제 무엇을 해야 하나요?
좋은 질문입니다! 다음 단계는 모델 자산을 앱에 번들로 묶어 대상 엣지 장치(모바일, IoT, 컴퓨팅 등)에 배포하는 것입니다. 이를 수행하는 방법에 대한 샘플 앱 이 있으며, 더 많은 샘플 앱을 제공하기 위해 작업 중입니다. 특히 Qualcomm® AI Engine Direct 을 사용할 때 .bin 파일을 통합하는 방법에 대해서는 이 문서 를 확인하세요. 이 주제에 대한 더 많은 샘플 앱과 정보를 추가하기 위해 적극적으로 작업 중입니다. Rb3Gen2에 배포하는 IoT 고객의 경우, AI Hub 에서 최적화된 모델과 함께 Foundries.io를 활용하는 것을 권장합니다.
AI Hub에 게시된 모델의 라이선스 조건은 무엇인가요? 이 모델을 내 앱에서 사용하고 사용자에게 배포할 수 있나요?
AI Hub Models는 사전 최적화된 오픈 소스 모델 컬렉션을 제공합니다. 각 모델의 라이선스는 해당 모델 페이지에서 확인할 수 있습니다.
내 모델을 가져오면 라이선스 조건은 어떻게 되나요? 이제 Qualcomm의 IP인가요?
AI Hub는 장치에 맞게 모델을 최적화하는 플랫폼입니다. “자신의 모델을 가져오는 경우”, AI Hub에서 얻은 배포 자산은 일반적으로 모델과 동일한 배포 라이선스를 가집니다. 자신의 IP인 경우 모델을 배포할 수 있습니다. 자세한 내용은 서비스 약관에서 확인할 수 있습니다.
AI Hub 또는 AI Hub Models를 프로덕션 애플리케이션에서 사용하거나 모델 테스트를 위해 AI Hub에 통합하는 데 수수료가 있나요?
AI Hub, 우리의 플랫폼은 현재 완전히 무료로 사용할 수 있습니다. 모델을 제출하고, 컴파일하고, 성능을 프로파일링하고 반복하며, 추론 작업을 제출하여 정확성을 확인하고, 앱에 번들로 묶을 대상 자산을 다운로드하는 것을 권장합니다.
우리의 모델 컬렉션에는 라이선스에 따라 구매해야 하는 특정 모델이 있습니다. 자세한 내용은 문의해 주세요. aihub.qualcomm.com에서 ‘download now’ 로 표시된 모델은 무료로 사용할 수 있습니다. 모델 페이지에 나열된 라이선스를 확인하고 해당 라이선스를 준수하여 사용하세요.
AI Hub가 클라우드에서 모델을 실행하는 경우, 안전한가요? 내가 업로드한 모델을 다른 사용자가 볼 수 있나요?
AI Hub를 통해 수행하는 모든 작업은 명시적으로 다른 사용자와 공유하지 않는 한 개인 정보로 안전하게 보호됩니다. 여기에는 업로드된 모든 데이터셋과 모델, AI Hub 작업을 통해 생성된 모델, 데이터셋, 지표가 포함됩니다. 작업 완료 후 고객의 아티팩트는 물리적 장치의 임시 저장소 및 기타 클라우드 컴퓨팅 환경에서 삭제됩니다. 다른 사용자는 귀하의 개인 정보를 볼 수 없습니다.
퀄컴이 데이터를 수집하고 사용하는 방법에 대한 자세한 내용은 Qualcomm privacy policy 을 참조하시고, 추가 문의 사항이 있으시면 email us 으로 이메일을 보내주세요.
팀 구성원을 내 조직에 추가하려면 어떻게 하나요?
각 사용자는 자신의 조직을 가지고 있으며, 사용자의 모델과 데이터는 조직 내에서 안전하게 보관되며, 사용자가 조직에 추가한 사람들만 접근할 수 있습니다. AI Hub에서 조직에 누구를 추가하고 싶은지 알려주시면, 그들이 귀하의 작업을 볼 수 있고 그 반대도 가능합니다.
특정 작업에 누군가를 추가하려면, 작업의 오른쪽 상단에 있는 공유 버튼을 사용하여 그들의 이메일 주소를 추가하는 것을 권장합니다.
AI Hub의 변경 사항을 어떻게 알 수 있나요?
릴리스 노트를 AI Hub Slack 에 게시합니다! 또한 문서 에서 확인할 수 있습니다.
모델 형식
왜 Qualcomm® AI Hub Models 는 일부 모델에 대해 TensorFlow Lite 결과만 제공하나요?
사전 최적화된 100개 이상의 모델 컬렉션을 방문하면 모델에 따라 TensorFlow Lite 또는 Qualcomm® AI Engine Direct 결과만 볼 수 있습니다. 두 경로에 대한 성능 결과를 제공하기 위해 작업 중이며, 이 경우 드롭다운에서 TorchScript → TensorFlow Lite 및 TorchScript → Qualcomm® AI Engine Direct 성능 수치를 선택할 수 있습니다. 또한 Compute Models 를 방문하면 해당되는 경우 TorchScript → ONNX Runtime 성능 결과도 볼 수 있습니다.
어떤 경로를 추천하나요? TensorFlow Lite, ONNX Runtime 또는 Qualcomm® AI Engine Direct?
모델에 따라 한 경로가 다른 경로보다 빠른 알려진 문제가 있습니다. 우리의 지속적인 목표는 이러한 문제를 추적하고 해결하는 것입니다. 대부분의 모델에 대해 최적화되면 거의 동일한 성능을 기대할 수 있습니다. 결국 모든 경로는 동일한 QNN과 동일한 하드웨어로 이어지므로 근본적으로 다른 점은 없습니다. TensorFlow Lite 는 TensorFlow Lite Delegate를 통해 Hexagon NPU에 액세스하고, ONNX Runtime 는 ONNX 실행 공급자를 통해 Hexagon NPU에 액세스하며, Qualcomm® AI Engine Direct 은 물론 Hexagon NPU를 활용합니다.
모바일 장치에 배포하는 Android 개발자에게는 TensorFlow Lite 를, 노트북에 배포하는 Windows 개발자에게는 ONNX Runtime 를, SoC/운영 체제에 따라 Qualcomm® AI Engine Direct 을 추천합니다. 대상 장치에 가장 적합한 성능을 제공하는 경로를 사용해보는 것을 강력히 권장합니다.
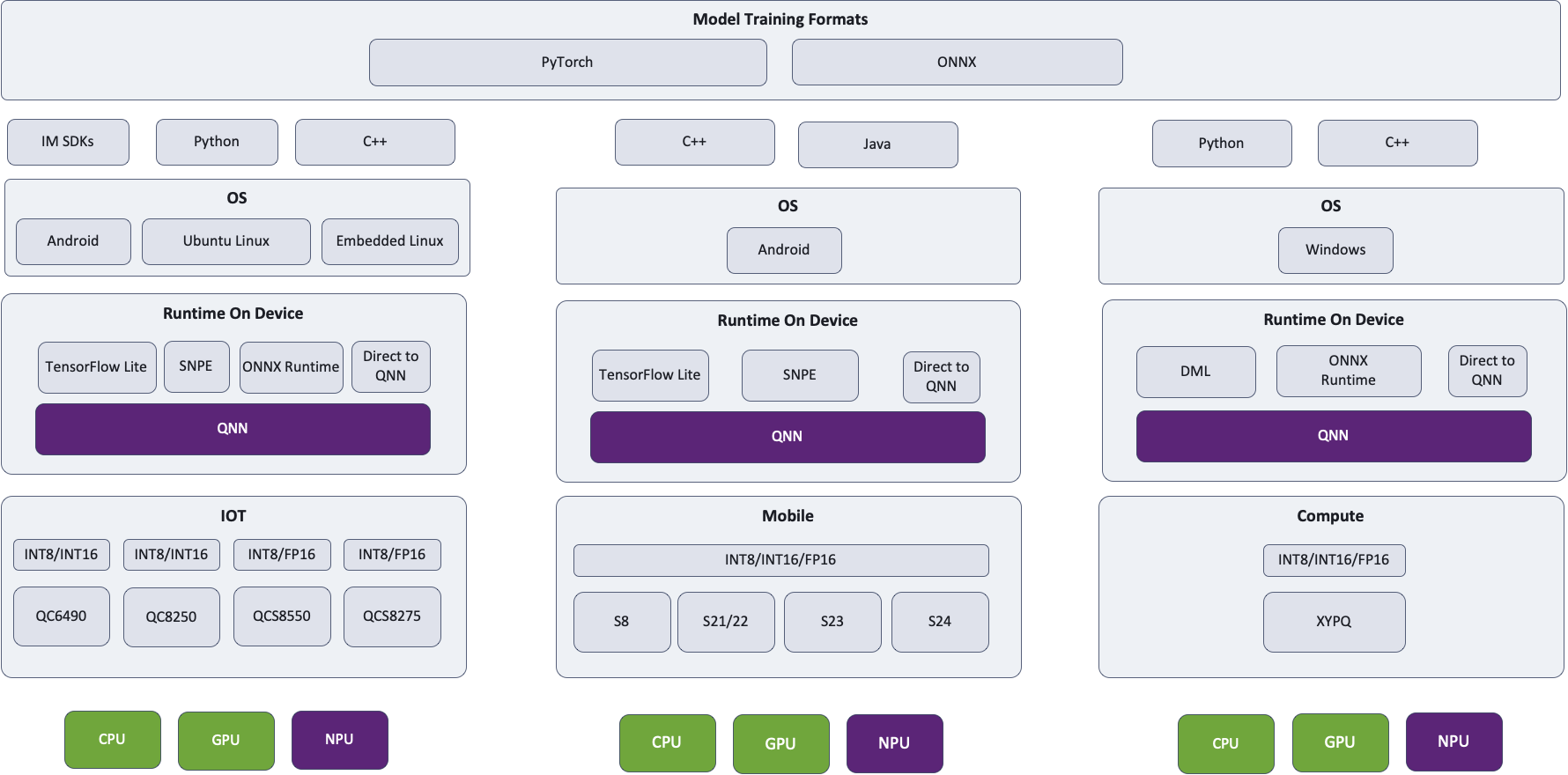
선택한 경로와 런타임에 관계없이 QNN이 사용되고 Hexagon NPU가 적용되는 아키텍처 다이어그램을 확인하세요. Hub는 항상 모델을 가장 최적의 컴퓨팅 유닛에서 실행합니다.
어떤 Qualcomm® AI Engine Direct 모델 형식을 사용해야 하나요?
Qualcomm® AI Engine Direct SDK는 장치에서 실행하기 위한 세 가지 형식을 지원합니다: 모델 라이브러리(.so 및 .dll), 컨텍스트 바이너리(.bin) 및 딥 러닝 컨테이너(.dlc). 이러한 형식 간에는 런타임 성능에 영향을 미칠 수 있는 중요한 차이점이 있습니다.
모델 라이브러리(
--target_runtime qnn_lib_aarch64_android)는 단일 함수를 내보내는 동적 라이브러리입니다. 이를 호출하면 QNN 그래프 빌딩 기능을 사용하여 모델을 인스턴스화합니다. 이 형식은 OS별이지만, 실행 중인 장치에 최적화된 최종 그래프를 보장하여 최상의 추론 성능을 제공합니다.딥 러닝 컨테이너(DLC)는 모델 라이브러리와 유사하게 네트워크의 SoC 독립적 표현을 포함합니다. 특정 대상 SoC 세트를 위한 컨텍스트 바이너리를 추가로 포함할 수 있지만, 이는 아직 일반적으로 사용되지 않습니다. 일반적으로 이 OS 독립적 형식은 장치별 최적화 전에 QNN 수준의 그래프 데이터 구조 구성을 구동하는 데 사용됩니다.
컨텍스트 바이너리는 OS에 구애받지 않는 HTP 전용 표현입니다. 이는 모델 라이브러리를 로드하고, 특정 SoC에 대한 그래프를 준비하고 (즉, 특정 HTP에 대해 Hexagon 컴파일러를 호출하도록 QNN을 허용), 결과 데이터 구조를 저장하는 것과 동일합니다. Hexagon 컴파일러는 사용 중인 HTP에 대한 가정을 하기 때문에, 컨텍스트 바이너리는 특정 HTP를 대상으로 할 때만 최상의 성능을 제공합니다. 구형 장치를 위해 빌드된 바이너리를 최신 칩에서 사용할 수 있지만, 성능이 저하될 수 있습니다.
최상의 성능을 달성하려면
qnn-context-binary-generator에 올바른soc_model을 지정해야 합니다. Qualcomm® AI Engine Direct Overview 에 있는 지원되는 Snapdragon 장치 표를 참조하여 올바른 값을 찾을 수 있습니다. 또한 SDK의docs/QNN/index.html에서Overview링크를 따라 가도 있습니다. 또한 Qualcomm® SoC를 대상으로 하는 모든 Qualcomm® AI Hub 런타임 로그의 상단 근처에도 인쇄되어 있습니다.
Qualcomm® AI Engine Direct 모델 형식 요약
형식 |
백엔드 |
OS에 구애받지 않음 |
SoC에 구애받지 않음 |
로드 시간 |
추론 성능 |
|---|---|---|---|---|---|
라이브러리 |
모든 백엔드 |
아니요 |
예 |
더 오래 걸리는 |
최적 |
DLC |
모든 백엔드 |
예 |
예 |
더 오래 걸리는 [1] |
최적 |
컨텍스트 바이너리 |
HTP |
예 |
아니요 |
가장 빠른 |
최적의 [2] |
프록시 장치에서 실제 하드웨어로 자산을 배포할 수 있나요?
요약 – TensorFlow Lite 및 ONNX Runtime 자산은 괜찮지만, QNN 모델 형식에는 문제가 있을 수 있습니다.
과거에는 프록시 장치가 AI Hub에 추가되어 성능 특성이 유사한 SoC를 가진 장치에 대한 프로파일링 및 추론 접근을 제공했습니다. 예를 들어, RB3 Gen 2에 있는 QCS6490은 여러 모바일 장치에 있는 SM7325와 본질적으로 동일한 칩입니다. 이는 벤치마킹 및 정확도 평가에 매우 유용할 수 있지만, QNN 모델 형식을 생성할 때 문제가 발생할 수 있습니다:
모델 라이브러리는 OS별로 다릅니다. 프록시 장치는 일반적으로 Android를 실행하지만, 실제 장치는 Linux를 사용할 수 있습니다.
컨텍스트 바이너리는 SoC별로 다릅니다. 프록시 장치를 대상으로 하는 것이 실제 장치에서 좋은 성능을 제공할 것으로 예상되지만, 이는 문서화된 보장이 아닙니다.
일부 경우에는 완전히 다른 QNN SDK 버전이 사용됩니다. 예를 들어, 모든 자동차 프록시 장치는 모바일 장치이지만, 모든 Cockpit, ADAS 및 Flex 장치는 동일한 세대의 자동차 및 모바일 칩 간의 차이를 알고 있는 특정 자동차 SDK를 사용해야 합니다 (예: SA8295P의 V68 HTP에서 fp16 지원).
다행히도 서드 파티 프레임워크는 로드 시 최적화를 수행하여 이러한 문제를 모두 피할 수 있으므로 TensorFlow Lite 및 ONNX Runtime 자산을 이 상황에서 배포하는 것이 좋습니다.
옵션 전달
컴퓨팅 유닛을 어떻게 지정하나요?
AI Hub에서 작업을 제출할 때 --compute_unit <units> 옵션을 사용하여 모델이 실행될 컴퓨팅 유닛을 지정할 수 있습니다. 여러 컴퓨팅 유닛을 지정하려면 쉼표로 구분하여 --compute_unit npu,cpu 와 같이 입력하세요. 이 주제에 대한 동영상 가이드 를 시청하는 것을 권장합니다.
대상 런타임을 어떻게 지정하나요?
Qualcomm® AI Hub 는 TensorFlow Lite, ONNX Runtime 및 Qualcomm® AI Engine Direct (컨텍스트 바이너리 및 모델 라이브러리)를 대상 런타임으로 지원합니다. 컴파일 작업을 제출할 때 --target_runtime <runtime> 옵션을 사용하여 런타임을 지정하세요. 이 주제에 대한 동영상 가이드 를 확인하는 것을 권장합니다.
NPU를 활용하고 있는지 어떻게 확인하나요?
각 대상 런타임은 사용 가능한 하드웨어를 최대한 활용하기 위한 자체 전략을 가지고 있습니다. 성능과 기능 사이에는 트레이드오프가 있습니다: NPU는 최고의 성능을 제공하지만, 계산할 수 있는 것이 가장 제한적입니다. 반면에 CPU는 신경망 추론에 최적화되어 있지 않지만, 모든 작업을 실행할 수 있습니다. 여러 하드웨어 백엔드를 지원하는 런타임은 일반적으로 가능한 한 많은 네트워크를 NPU에서 실행한 후 GPU 또는 CPU로 폴백합니다.
NPU 사용을 활성화하려면 런타임을 구성하고 네트워크가 지원되지 않는 작업이나 매개변수를 사용하지 않도록 해야 합니다.
기본적으로 AI Hub는 폴백을 지원하는 런타임을 NPU를 사용하도록 구성한 후 GPU 및/또는 CPU로 폴백합니다. NPU 사용을 필수로 지정하려면 컴파일/런타임 옵션 --compute_unit npu 를 지정하세요. 또한 qnn_lib_aarch64_android 와 같은 QNN 대상 런타임을 사용하는 것을 고려하세요.
NPU에서 레이어가 제외되는 일반적인 이유는 지원되지 않는 연산자(op) 또는 지원되지 않는 rank 때문입니다. (특히 rank ≥ 5 인 경우에는 지원이 제한적일 수 있습니다.) 이러한 상황이 이 기종 디스패치를 지원하는 런타임(예: TensorFlow Lite)에서 발생하면, 해당 레이어는 GPU 또는 CPU로 자동 전환되어 실행됩니다. 경우에 따라 전체 네트워크가 NPU에서 제외될 수 있으며, 이는 온디바이스에서 네트워크를 준비하는 과정 중 예기치 않은 오류가 발생했을 때 일어날 수 있습니다. 이 경우 네트워크는 GPU 또는 CPU에서 실행됩니다. 만약 이러한 상황이 발생하면, AI Hub Slack 채널을 통해 연락 주시기 바랍니다. 저희가 해당 작업을 확인해 드리겠습니다.
최적화 옵션을 어떻게 지정하나요?
기본적으로 AI Hub는 항상 런타임 성능을 최적화합니다. 때때로, 최적화 시간이 너무 오래 걸려 작업이 시간 초과되는 경우가 있습니다: 일부 대형 모델은 Hexagon 컴파일러가 처리할 작업이 너무 많아 작업이 시간 초과될 수 있습니다. 드물게, 높은 최적화 수준이 더 나쁜 코드를 생성할 수 있습니다. 이러한 경우 최적화 수준을 낮추는 것이 좋습니다. 방법은 대상 런타임 환경에 따라 다릅니다.
NPU를 대상으로 하는 Qualcomm® AI Engine Direct 의 경우 (예:
--target_runtime=qnn_lib_aarch64_android --compute_unit all)--qnn_options=default_graph_htp_optimization_value=x를 사용하여x를1또는2로 설정하세요.qnn_lib_*를 사용할 때 Hexagon 컴파일은 장치에서 발생하지만,qnn_context_binary를 대상으로 할 때는 모델 변환 중에 미리 실행됩니다.NPU로 성공적으로 위임된
tflite를 대상으로 하는 경우 (즉,--target_runtime=tflite) QNN 최적화 수준을1로 설정하는 효과가 있는--tflite_options=kHtpOptimizeForPrepare를 사용합니다.tflite를 대상으로 할 때 Hexagon 컴파일은 항상 장치에서 발생합니다.
작업 실패 및 알려진 문제
컴파일 작업이 누락된 작업 오류 메시지와 함께 실패했습니다. 어떻게 해야 하나요?
ONNX에서 Tensorflow로 변환 중 오류 발생: 작업 'xx'가 아직 구현되지 않았습니다 와 같은 오류가 발생한 경우 AI Hub Slack 에 문의해 주세요. 작업 지원 추가를 우선적으로 처리할 수 있습니다 (또는 이미 진행 중일 수 있습니다). 그렇지 않은 경우, 해당하는 경우 해결 방법을 제공해 드릴 수 있습니다.
문서에 나열된 옵션을 전달했음에도 불구하고 작업이 실패했습니다. 어떻게 해야 하나요?
올바른 작업 유형 (예: 컴파일 vs 프로파일)인지 확인하세요. 예를 들어, --quantize_full_type 은 컴파일 작업 옵션입니다; 프로파일 작업에 전달하면 실패합니다. 여전히 문제가 발생하면 AI Hub Slack 에 문의해 주세요.
Hugging Face에서 가져온 모델이 “DictConstruct” 지원되지 않음으로 인해 실패했습니다. 어떻게 해야 하나요?
model.config.return_dict = False 로 설정하는 것을 권장합니다. 기본값은 true 입니다. Hub는 현재 사전 형식을 자동으로 처리하지 않습니다. 이는 백로그에 있습니다. 그동안 사전을 튜플로 변환하는 래퍼 모듈을 작성하는 것도 해결 방법이 될 수 있습니다.
내 프로파일 작업이 [0-9]+ 값의 요청 기능 아키텍처가 지원되지 않는다는 오류로 실패했습니다. 이게 무슨 뜻인가요?
이 오류는 컨텍스트 바이너리가 대상 장치가 지원하는 Hexagon 아키텍처의 최신 버전으로 빌드될 때 발생합니다. 이 문제를 해결하려면 프로파일링 또는 추론에 사용할 장치로 소스 모델을 다시 컴파일하세요.
내 프로파일 작업이 오류 코드 3110을 인용하며 실패했습니다. 왜 이런 일이 발생했나요?
이 오류는 모델을 장치에 준비할 수 없음을 의미합니다. 몇 가지 이유가 있을 수 있습니다:
부동 소수점이 지원되지 않음. 유형 <type> 의 노드 <name> 에 대해 오류 코드 3110으로 실패했습니다. 3110 오류는 노드의 입력 또는 출력 유형이 QNN 백엔드에서 지원되지 않을 때 발생합니다. 이는 종종 제대로 양자화되지 않은 노드나 양자화되지 않은 텐서가 통과될 때 발생하여 오류를 초래합니다. 이 문제를 해결하려면 모델을 양자화(또는 재양자화)하세요. 연산자 정의 및 제약 조건은 HTP Backend Op Definition Supplement 에서 찾을 수 있습니다.
지원되지 않는 순위. 많은 연산자는 <5D만 지원합니다. 일부는 5D를 지원하고, >5D는 지원하지 않습니다.
지원되지 않는 유형. 많은 연산자는 모든 유형을 지원하지 않습니다. 이 오류는 [u]int32 레이어에서 매우 흔합니다.
프로파일 작업이 실패했습니다. Error code: 1002 at location qnn_model.cc:167 onnxruntime::qnn::QnnModel::FinalizeGraphs. 어떻게 해야 하나요?
런타임 로그에서 유용한 정보를 제공하지 않는 경우, 다음 옵션을 사용하여 다시 프로파일링하는 것을 권장합니다: --runtime_debug=true --max_profiler_iterations=1. 이러한 설정을 통해 런타임 로그가 문제의 원인에 대한 추가 정보를 제공하는 경우가 많습니다.
배포
내 모델이 Hub에서보다 장치에서 더 느리게 실행되는 이유는 무엇인가요?
Hub에서는 가능한 한 빠르게 모델을 실행할 수 있는 현실적인 환경을 만들려고 합니다. 개발자가 사용자 인터페이스가 있는 앱에 가장 자주 배포할 것이라고 가정하고 프로파일러를 구현했습니다. 기본적으로 가능한 가장 높은 전력 설정에서 실행하여 가능한 가장 빠른 추론을 달성합니다. 이러한 선택의 결과를 살펴보겠습니다.
스케줄링 우선순위
Hub의 프로파일러는 모든 지원되는 모바일 및 자동차 장치에서 Android 애플리케이션입니다. 이는 커널 수준에서 우선적인 스케줄링 혜택을 받는다는 것을 의미합니다. Android는 기본적으로 응답성 있는 사용자 인터페이스를 제공하기 위해 이를 수행합니다. 이는 adb shell 을 통해 실행될 수 있는 qnn-net-run 포함한 CLI 도구에는 적용되지 않습니다. 이는 GUI와 CLI 도구 간의 성능 격차를 초래합니다. 영향은 상당할 수 있습니다. 65개의 다른 Android 장치에서 MobileNetV2를 실행하는 실험에서, 프로덕션에서 사용된 GUI와 비교하여 CLI 버전의 프로파일러를 사용할 때 평균 [3] 9.7%의 속도 저하가 발견되었습니다. GUI 애플리케이션과 동일한 스케줄링 우선순위로 CLI 도구를 실행하려면 루트 권한으로 nice -n -10 YOUR_TOOL 을 사용하세요.
전력 설정
기본적으로 Hub는 모든 모바일 장치에서 BURST 전력 설정을 요청합니다. 이는 일반적으로 기본값보다 훨씬 빠른 실행을 초래합니다. 앱에서 이를 활성화하는 단계는 사용 중인 ML 프레임워크에 따라 다릅니다. ONNX Runtime 및 TensorFlow Lite 는 이를 대신 설정하는 설정을 가지고 있습니다. Qualcomm® AI Engine Direct 의 경우, 위 페이지에 설명된 대로 전압 코너 및 기타 옵션을 개별적으로 설정해야 합니다.
프로파일 설정
상세한 프로파일링 데이터를 수집하는 것 (예: qnn-net-run --profiling_level detailed)은 상당한 오버헤드를 초래할 수 있습니다. 네트워크 레이어의 상대적인 런타임을 비교할 때만 이러한 설정을 사용하세요.
기타 설정
프레임워크 기본값에서 AI Hub가 재정의하는 설정 (사용자가 지정한 설정 포함)은 추론 및 프로파일 작업 페이지의 “런타임 구성” 설정에서 찾을 수 있습니다. fp16_relaxed_precision 이 기본으로 활성화 되어 있는 부분을 주목하세요.
HTP를 사용하려고 할 때 오류 1008 이 발생하는 이유는 무엇인가요?
오류 1008, 즉 QNN_COMMON_ERROR_INCOMPATIBLE_BINARIES 는 일반적으로 HTP 초기화 실패를 나타냅니다. 대부분의 경우, HTP [4] 에서 실행되는 코드를 포함하는 라이브러리를 찾을 수 없기 때문입니다. 대부분의 플랫폼에서 환경 변수 ADSP_LIBRARY_PATH 는 장치의 DSP 아키텍처에 해당하는 스켈레톤 파일이 포함된 디렉토리로 설정되어야 합니다 [5]. 자세한 내용은 이 QNN 튜토리얼 에서 확인할 수 있습니다.
여전히 작동하지 않습니다; Windows를 사용 중입니다
확인해야 할 추가 사항이 두 가지 있습니다.
첫째, 스켈레톤 파일은 실제로 QnnHtp.dll 과 동일한 디렉토리에 있어야 합니다. ADSP_LIBRARY_PATH 가 다른 플랫폼에서와 동일하게 작동한다고 제안하는 문서를 보았지만, 우리의 경험에 따르면 Windows에서는 무시됩니다.
둘째, Windows에서는 스켈레톤과 함께 배포된 .cat 파일이 있어야 합니다: 애플리케이션의 실행 파일 디렉토리로 스켈레톤 라이브러리를 복사할 때 .cat 파일을 잊지 마세요.
자동차 장치에서 HTP를 사용하는 방법은 무엇인가요?
자동차 게스트 VM에서 HTP를 사용하려면 위에서 설명한 대로 ADSP_LIBRARY_PATH 를 설정하는 것 외에도 추가 단계가 필요합니다: 두 파일을 QNX 호스트에서 게스트 VM으로 복사해야 합니다. 구체적으로, 이러한 파일은 일반적으로 적절한 스켈레톤 라이브러리가 포함된 디렉토리에 복사되어야 합니다.
/dspfw 및 /dsplib 파티션이 있는 대상의 경우:
/dsplib/image/dsp/cdsp0/libc++.so.1/dsplib/image/dsp/cdsp0/libc++abi.so.1
/dspfw 및 /dsplib 파티션이 없는 대상의 경우:
/mnt/etc/images/cdsp0/libc++.so.1/mnt/etc/images/cdsp0/libc++abi.so.1
이 문서에서 다루지 않은 추가 질문이 있는 경우, AI Hub Slack 에 문의해 주세요.