Qualcomm® AI Hub
Qualcomm® AI Hub 는 비전, 오디오 및 음성 사용 사례에 대한 온디바이스 러닝 모델을 최적화, 검증 및 배포하는 데 도움이 됩니다.
Qualcomm® AI Hub 를 사용하면 다음 작업을 수행할 수 있습니다.
PyTorch 및 ONNX 와 같은 프레임워크에서 훈련된 모델을 변환하여 Qualcomm® 장치에서 온디바이스 성능을 최적화합니다.
프로파일 모델 온디바이스 런타임, 로드 시간, 컴퓨팅 단위 활용도를 포함한 자세한 지표를 얻습니다.
온디바이스 추론을 수행하여 수치적 정확성을 확인합니다.
Qualcomm® AI Engine Direct, TensorFlow Lite, 또는 ONNX Runtime 를 사용하여 모델을 쉽게 배포하세요.
Qualcomm® AI Hub Models 저장소에는 Qualcomm® AI Hub 를 사용하여 Qualcomm® 기기에서 모델을 최적화, 검증하고 배포하는 예제 모델 컬렉션이 포함되어 있습니다.
어떻게 작동하나요?
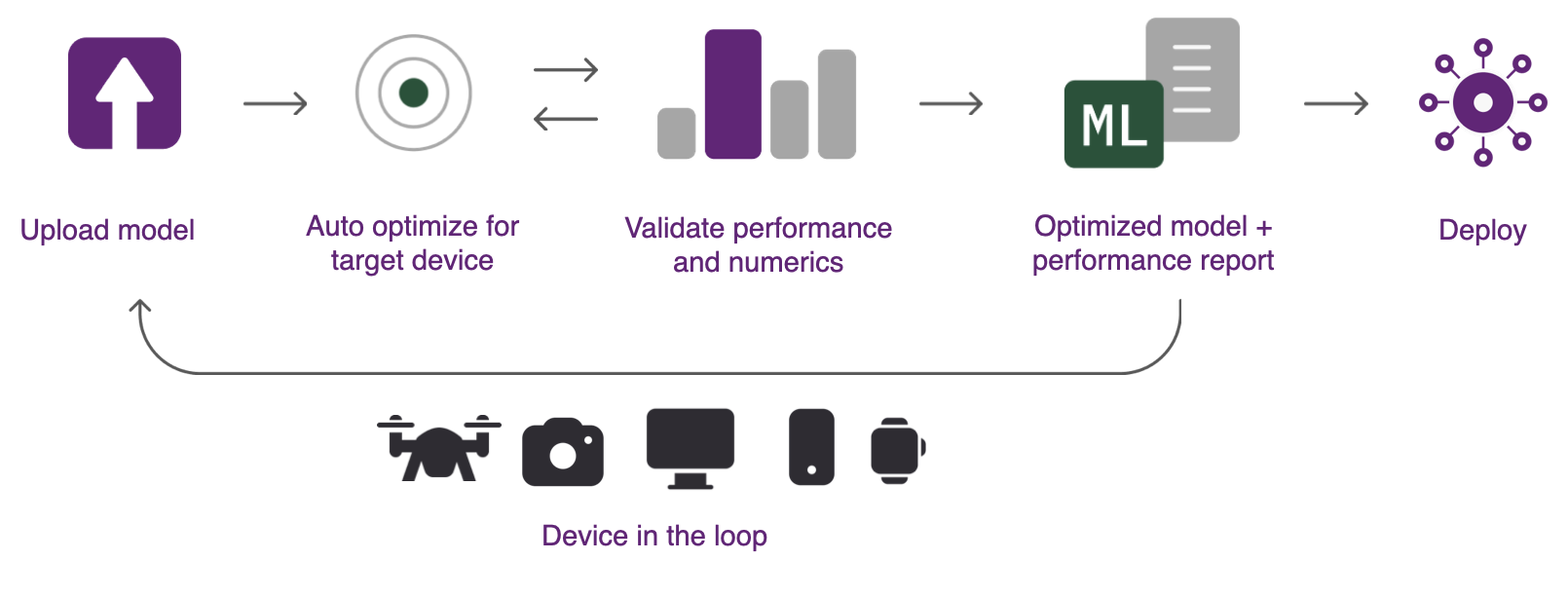
Qualcomm® AI Hub 는 소스 프레임워크에서 디바이스 런타임으로의 모델 변환을 자동으로 처리하고, 하드웨어 인식 최적화를 적용하며, 물리적 성능/수치 검증을 수행합니다. 이 시스템은 클라우드에서 디바이스를 자동으로 프로비저닝하여 디바이스 내 프로파일링 및 추론을 수행합니다. 다음 이미지는 Qualcomm® AI Hub 를 사용하여 모델을 분석하는 단계들을 보여줍니다.
Qualcomm® AI Hub 을 사용하려면 다음이 필요합니다:
PyTorch, TorchScript, ONNX 또는 TensorFlow Lite 형식의 훈련된 모델입니다.
배포 대상에 대한 실무 지식이 필요합니다. 이는 특정 기기(예: Samsung Galaxy S23 Ultra) 또는 여러 기기 범주일 수 있습니다.
다음 세 단계를 사용하여 훈련된 모델을 Qualcomm® 장치에 배포할 수 있습니다.
- 1단계: 온디바이스 실행 최적화
이 시스템은 선택된 대상 플랫폼에 대해 훈련된 모델을 최적화할 수 있는 호스팅 컴파일러 도구 모음을 포함합니다. 그런 다음 하드웨어 인식 최적화를 수행하여 대상 하드웨어가 가장 잘 활용되도록 합니다. 모델은 Qualcomm® AI Engine Direct, TensorFlow Lite 또는 ONNX Runtime 에 배포되도록 최적화할 수 있습니다. 모든 형식 변환은 자동으로 처리됩니다.
- 2단계: 온디바이스 추론 수행
시스템은 컴파일된 모델을 물리적 장치에서 실행하여 모델 계층의 컴퓨팅 단위 매핑, 추론 지연 시간, 최대 메모리 사용량과 같은 메트릭을 수집할 수 있습니다. 도구는 또한 수치적 정확성을 검증하기 위해 입력 데이터를 사용하여 모델을 실행할 수 있습니다. 모든 분석은 클라우드에서 자동으로 프로비저닝된 실제 하드웨어에서 수행됩니다.
- 3단계: 배포
모델 결과는 Qualcomm® AI Hub 에 표시되어 모델 성능을 이해하고 추가 개선 기회를 제공하는 통찰력을 제공합니다. 최적화된 모델은 다양한 플랫폼에 배포할 수 있습니다.
내용