工作原理
Qualcomm® AI Hub 幫助優化、驗證和部署用於視覺、音頻和語音應用的機器學習模型到設備上。
Qualcomm® AI Hub 測量什麼?
Qualcomm® AI Hub 上的分析文件作業測量在各種實體設備上運行優化模型所需的資源。它收集的指標專門設計用來幫助您確定模型是否符合您的時間和內存預算。
概述
分析文件是根據在用戶設備上運行目標模型所需的四個步驟收集的。
編譯 -- 在支持設備上編譯的平台上,Hub 會在系統提供足夠穩定和資源尊重的工具鏈時報告相關指標。
首次應用加載 -- 第一次加載模型時,作業系統可能會進一步優化模型以適應運行的設備。例如,如果有神經處理單元(NPU)如 Qualcomm® Hexagon™ 處理器可用,模型將準備在該硬件上執行。結果通常會被暫存在記憶體,以加快後續加載速度。
後續應用加載 -- 從第二次開始加載模型時,可能會避免昂貴的設備上的優化運算。
推理 -- 模型加載後,Hub 會執行推理。分析文件作業準備隨機數據並多次緊密循環地執行模型。
以下描述的時間和內存指標是為每個步驟收集的。
時間
許多步驟只能合理地執行一次。例如,在 首次應用加載 後,通常不可能清除所有框架和操作系統緩存。因此,只有推理可以多次測量。
在多次迭代過程中,Hub 測量評估模型所需的時鐘時間。成本僅包括對推理框架的調用成本和少量開銷。
推理時間測量是一個微基準,其目的是將模型與其他噪音隔離,以便可以作為一個原子單元有意義地優化。輸入僅在每批次生成一次,並在多次迭代中重用。Hub 報告觀察到的最小時間,這導致更可重複的指標,排除了不會因模型優化而減少的噪音。
記憶體
有很多方法可以描述應用程序的內存使用情況。然而,大多數開發人員都希望知道從作業系統的角度來看,他們的應用程序的佔用空間。畢竟,這決定了應用程序是否會被終止或要求釋放內存。正如我們下面解釋的那樣,即使這樣也很難預測。為了提供清晰和全面的內存指標,Hub 報告範圍,這比單一數字指標更準確。
虛擬記憶體
現代的作業系統提供了一個在用戶程式和實體記憶體之間的抽象層,通稱為「虛擬記憶體」。當一個程式要求記憶體時,幾乎不會立即更新映射到實體記憶體。相反地,作業系統只會標記某些記憶體範圍已被分配,並且是「乾淨的」可以被使用。
記憶體處於「乾淨」狀態時,表示其內容尚未被寫入,因此如果系統記憶體不足,這些內容不需要被保留。當程序寫入記憶體時,記憶體變得「髒」,這意味著作業系統不能單獨丟棄其內容而不會造成數據遺失。如果一段「髒」記憶體在一段時間內未被訪問,作業系統可能會通過將數據寫入硬碟(交換)或壓縮記憶體來釋放相關的實體記憶體,使其變得更小,但暫時不可用。應用程序的「記憶體佔用量」是非乾淨記憶體的總和:「髒」記憶體、交換記憶體、和壓縮記憶體。
大多數類Unix操作系統,包括Android和Linux,都不保證虛擬記憶體能夠映射到實體儲存空間。如果全域使用率很高,需求可能會超過可用的實體記憶體和硬碟交換空間。當這種情況發生時,系統會嘗試通過終止佔用大量記憶體的程序來保持穩定性。Windows採取了不同的方法:當程序分配虛擬記憶體時,系統「承諾」將其內容存儲在實體記憶體和/或頁面檔案中,確保全域需求永遠不會超過系統容量。由於系統永遠不會耗盡記憶體,因此不需要終止過度分配的進程。
堆棧
作業系統必須管理現代設備上難以想像的大型虛擬地址空間。維護虛擬地址到任意小分配的映射所需的元數據對於內核來說將是不可承受的。因此,系統設有最小分配單位,即「頁」,通常範圍在4-16 KB之間。當然,程序通常創建的對象遠小於一個頁面。為了有效利用記憶體,malloc 用於將多個程序對象打包到一個或多個操作系統頁面中。
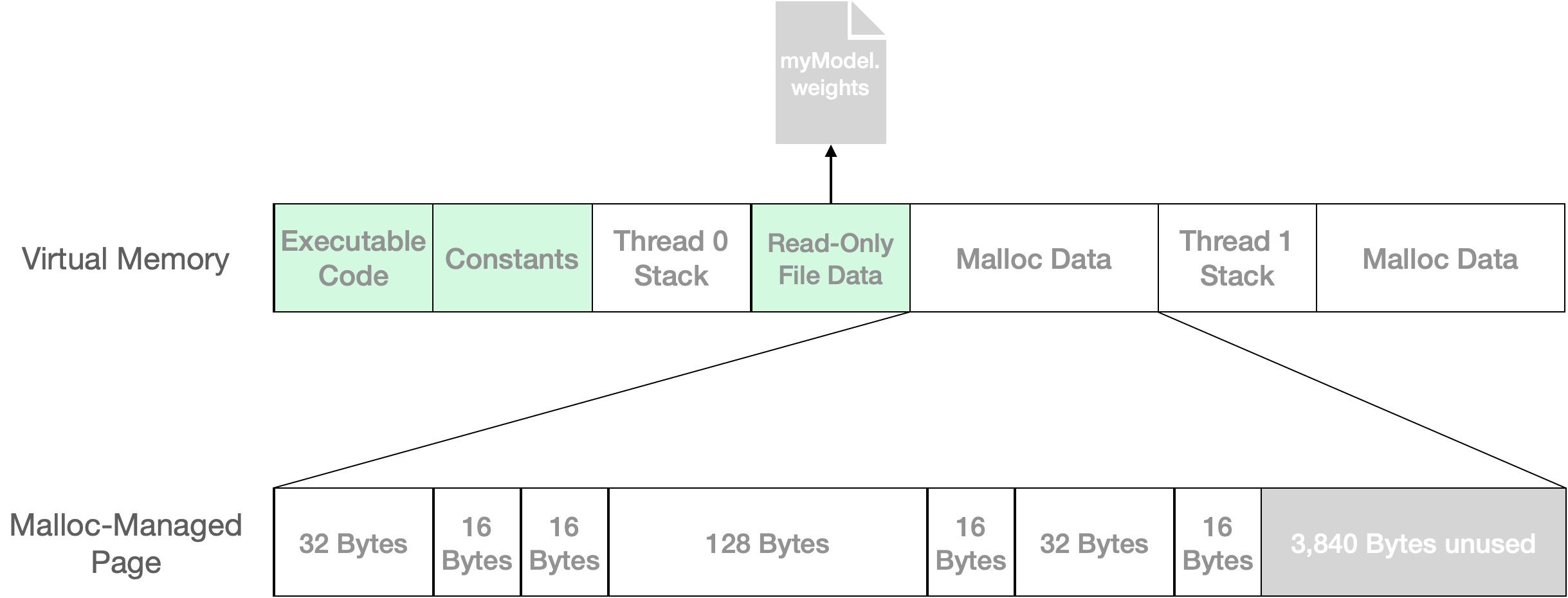
圖 1: 虛擬內存由操作系統按頁面單位分配,這些頁面可以是乾淨的(顯示為綠色)或非乾淨的。Malloc 是一個接口,用於將小對象有效地打包到這些大頁面中。在此示例中,256 字節的用戶數據被打包到單個 4,096 字節的頁面中,留下 3,840 字節可供未來調用 malloc 使用。
圖 1 顯示了一個簡化的虛擬內存地址空間。乾淨 區域是操作系統可以在不運行任何用戶代碼的情況下重新創建的區域。這通常是因為這些頁面由不變的文件支持或根本沒有被寫入。從某些操作系統的角度來看,非乾淨頁面構成了應用程序的內存佔用:如果您的應用程序有太多髒的、交換的和/或壓縮的頁面,則在系統內存不足時有被終止的風險。
大多數運行時數據由 malloc 管理,其髒頁面可能僅部分被利用。在此示例中,256 字節的用戶數據保存在一個 4 KB 的頁面中,但 3,840 字節未使用。在實際應用中,內存需求大的任務(如模型編譯和加載)可能會在 malloc 管理的頁面中留下大量未使用的空間。這些內存通常可以由後續步驟重用。
在計算內存佔用時,作業系統提供的工具和 API 不知道 malloc 管理的頁面中有多少未使用的內存。由於部分或全部未使用的內存可能會被重用,在 Android 上,Hub 報告的內存使用情況是一個範圍,在最佳情況下假設完全重用,在最糟情況下假設沒有重複使用。
如上所述,Windows 上的情況有所不同。由於系統不可能意外耗盡內存,因此沒有內存監視器可能會終止用戶的進程。因此,在 Windows 上,Hub 的內存使用指標假設已分配的堆棧空間不會被後續需求重用。 報告範圍的兩端都是進程提交費用,即虛擬內存分配的總和。包括工作集大小在內的其他指標可以在運行時日誌文件中找到。
峰值 與 增加
完成任務所需的內存通常超過結果的大小。考慮一個我們正在編譯模型的場景;假設編譯器中沒有內存洩漏,將需要一些內存將設備上的模型轉換為編譯模型,將工件留在儲存中,內存中沒有物件。如果編譯器佔用了 40 MB,我們會說它的 峰值 使用量為 40 MB,但穩定狀態 增加 的內存使用量為 0 Byte。
具體內存指標
綜合起來,分析文件作業將返回類似於表 1 中顯示的內存指標。示例中 CNN 模型的源為 54 MB,因此在設備上編譯期間使用約 163 MB 並不奇怪,但在編譯模型存放在硬碟後不再占用內存。增加 的上限報告了內存用量最高情況,即編譯後剩餘的 0.7 MB 未使用的 malloc 管理內存永遠不會被應用程序重用。同樣,應用程序加載模型後使用的數據量在首次和後續加載之間實際上可能沒有區別,儘管初始加載留下了更多未使用的 malloc 管理內存。這並不意外,因為初始加載可能做了更多工作,因此更多分配。
階段 |
峰值 |
增加 |
|---|---|---|
編譯 |
162.7 - 163.4 MB |
0.0 - 0.7 MB |
首次應用加載 |
1.7 - 2.8 MB |
0.6 - 1.7 MB |
後續應用加載 |
1.8 - 2.5 MB |
0.8 - 1.6 MB |
推理 |
629.6 - 630.6 MB |
378.7 - 379.6 MB |
在 Hub 中,我們展示了峰值範圍,這突出了您的模型對內存壓力的最重要貢獻,這可能會導致作業系統終止您的應用程序。這些和所有其他指標都可以在 Python 客戶端庫中找到。完整的內存和時間指標集顯示在表 2 中。
鍵 |
類型 |
單位 |
|---|---|---|
|
|
Bytes |
|
|
Bytes |
|
|
Bytes |
|
|
Bytes |
|
|
Bytes |
|
|
Bytes |
|
|
Bytes |
|
|
Bytes |
|
|
Microseconds |
|
|
Microseconds |
|
|
Microseconds |
|
|
Microseconds |