Qualcomm® AI Hub
Qualcomm® AI Hub helps to optimize, validate, and deploy machine learning models on-device for vision, audio, and speech use cases.
With Qualcomm® AI Hub, you can:
Convert trained models from frameworks like PyTorch and ONNX for optimized on-device performance on Qualcomm® devices.
Profile models on-device to obtain detailed metrics including runtime, load time, and compute unit utilization.
Verify numerical correctness by performing on-device inference.
Easily deploy models using Qualcomm® AI Engine Direct, TensorFlow Lite, or ONNX Runtime.
The Qualcomm® AI Hub Models repository contains a collection of example models that use Qualcomm® AI Hub to optimize, validate, and deploy models on Qualcomm® devices.
How does it work?
Qualcomm® AI Hub automatically handles model translation from source framework to device runtime, applying hardware-aware optimizations, and performs physical performance/numerical validation. The system automatically provisions devices in the cloud for on-device profiling and inference. The following image shows the steps taken to analyze a model using Qualcomm® AI Hub.
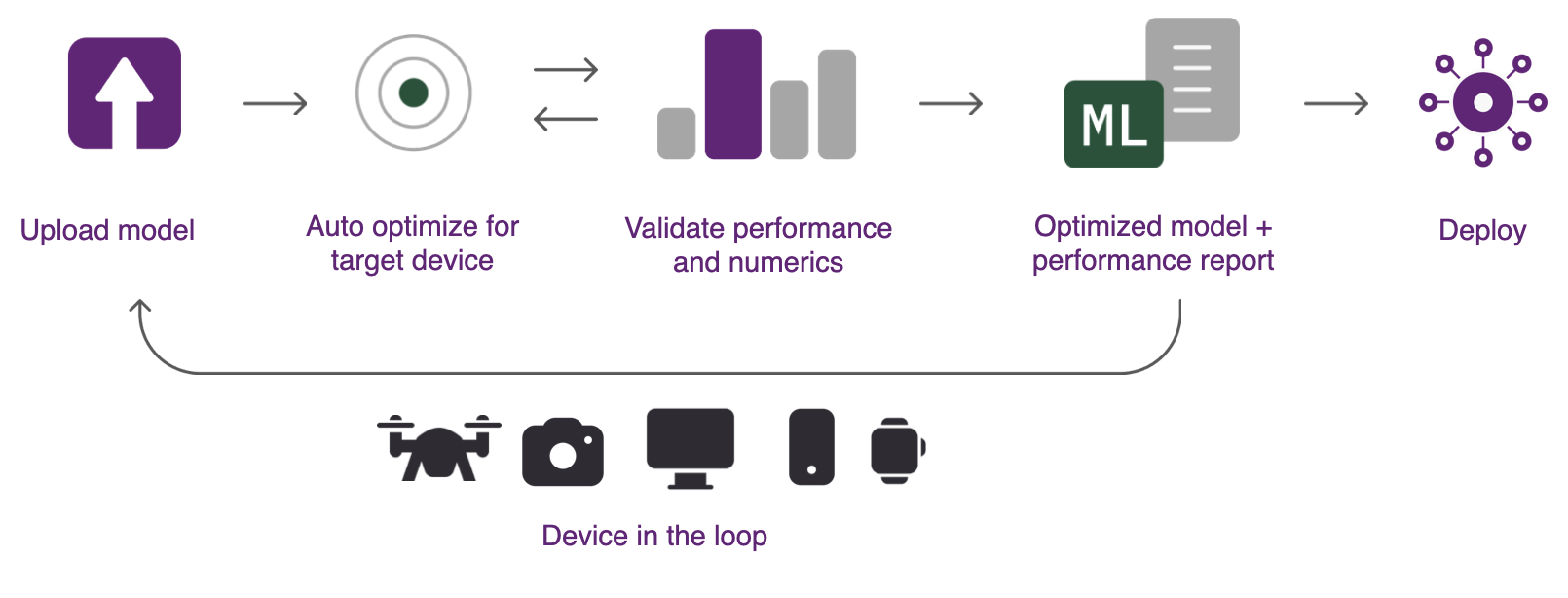
To use Qualcomm® AI Hub, you require:
A trained model which can be in PyTorch, TorchScript, ONNX or TensorFlow Lite format.
Working knowledge of the deployment target. This can be a specific device (e.g., Samsung Galaxy S23 Ultra) or a range of devices.
The following three steps can be used to deploy trained models to Qualcomm® devices:
- Step 1: Optimize for on-device execution
The system contains a collection of hosted compiler tools that can optimize a trained model for the chosen target platform. Hardware-aware optimizations are then performed to ensure the target hardware is best utilized. The models can be optimized for deployment on either Qualcomm® AI Engine Direct, TensorFlow Lite, or ONNX Runtime. All format conversions are automatically handled.
- Step 2: Perform on-device inference
The system can run the compiled model on a physical device to gather metrics such as the mapping of model layers to compute units, inference latency, and peak memory usage. The tools can also run the model using your input data in order to validate numerical correctness. All analyses are performed on real hardware automatically provisioned in the cloud.
- Step 3: Deploy
Model results are displayed on Qualcomm® AI Hub, providing insights to understand the model performance and opportunities for further improvements. The optimized model is available for deployment to a variety of platforms.
Additional Resources